Overview
애플리케이션을 개발하면 외부에서도 접근 가능하도록 클라우드 환경에 배포합니다.
이전에 포스팅 했던 AWS 1편에서는 마지막에 scp 명령어로 로컬에 존재하는 빌드 파일을 EC2 인스턴스로 복사한 후 ssh 로 접속해서 실행시켰습니다.
하지만 매 배포마다 이렇게 하면 굉장히 번거롭고 실수할 가능성도 높아집니다.
그래서 이런 수작업을 자동화하는 여러 가지 툴과 기법들이 등장했고 Github Actions 도 그 중 하나입니다.
Github Actions 에 대해서는 지난 포스팅 에서 한번 다룬 적이 있습니다.
이번에는 Github Actions 를 사용해서 AWS EC2 에 자동으로 배포하는 과정을 알아봅니다.
글은 다음과 같은 순서로 진행됩니다.
- Github Actions 에서 AWS 에 배포하는 방법
- AWS EC2 설정 추가
- AWS S3 버킷 생성
- AWS CodeDeploy 앱 생성 및 배포 설정
- Github Actions 에서 사용할 사용자 권한 추가
- AppSpec 파일 작성
- 배포 스크립트 작성
- Github Actions Workflow 작성
- Github 에서 push 로 배포하기
1. 배포 방법
main 브랜치에 Push 하면 자동으로 EC2 까지 배포되는 Workflow 를 만들어봅시다.
먼저 Workflow 를 작성하기 전에 어떤 방식으로 EC2 까지 배포가 이루어지는 지 전체적인 플로우를 알아야 합니다.
Github Actions 를 확인하면 CI 과정에서 했던 것처럼 aws.yml 이라는 기본 Workflow 를 제공합니다.
배포하는 방법은 여러 가지 있겠지만 AWS 의 경우 큰 흐름은 하나입니다.
소스 코드를 압축하여 AWS 스토리지에 저장 후 서버에 전달해서 실행한다
그리고 AWS 에서 공식적으로 가이드하는 방법은 크게 두 가지가 있습니다.
- AWS S3 빌드파일 압축해서 업로드 -> AWS EC2 배포 (CodeDeploy 활용)
- AWS ECR 에 도커 이미지 업로드 -> AWS ECS 배포 (Task Definition 활용)
1.1. 어떤 차이가 있을까?
우리는 EC2 인스턴스에 배포해야 하기 때문에 1번 방법을 사용합니다.
Github Actions 에서 제공하는 AWS Workflow 는 2번 방법을 안내하고 있어서 차이점을 먼저 알아봤습니다.
AWS ECR 은 Docker Image 를 저장하는 레지스트리고 AWS ECS 일종의 도커 컨테이너 서비스입니다.
AWS ECS 는 미리 정의한 Task Definition 을 기반으로 클러스터에 인스턴스를 생성하고 ECR 에 저장된 도커 이미지를 배포하는 등 인스턴스를 관리하며 스케일 인/아웃을 지원합니다.
여러 서버 인스턴스를 관리하기 위해선 더 편할 수 있으나 우리는 이미 존재하는 EC2 인스턴스에 배포하는 걸 목적으로 하기 때문에 1번 방법을 사용합니다.
1.2. 배포 과정
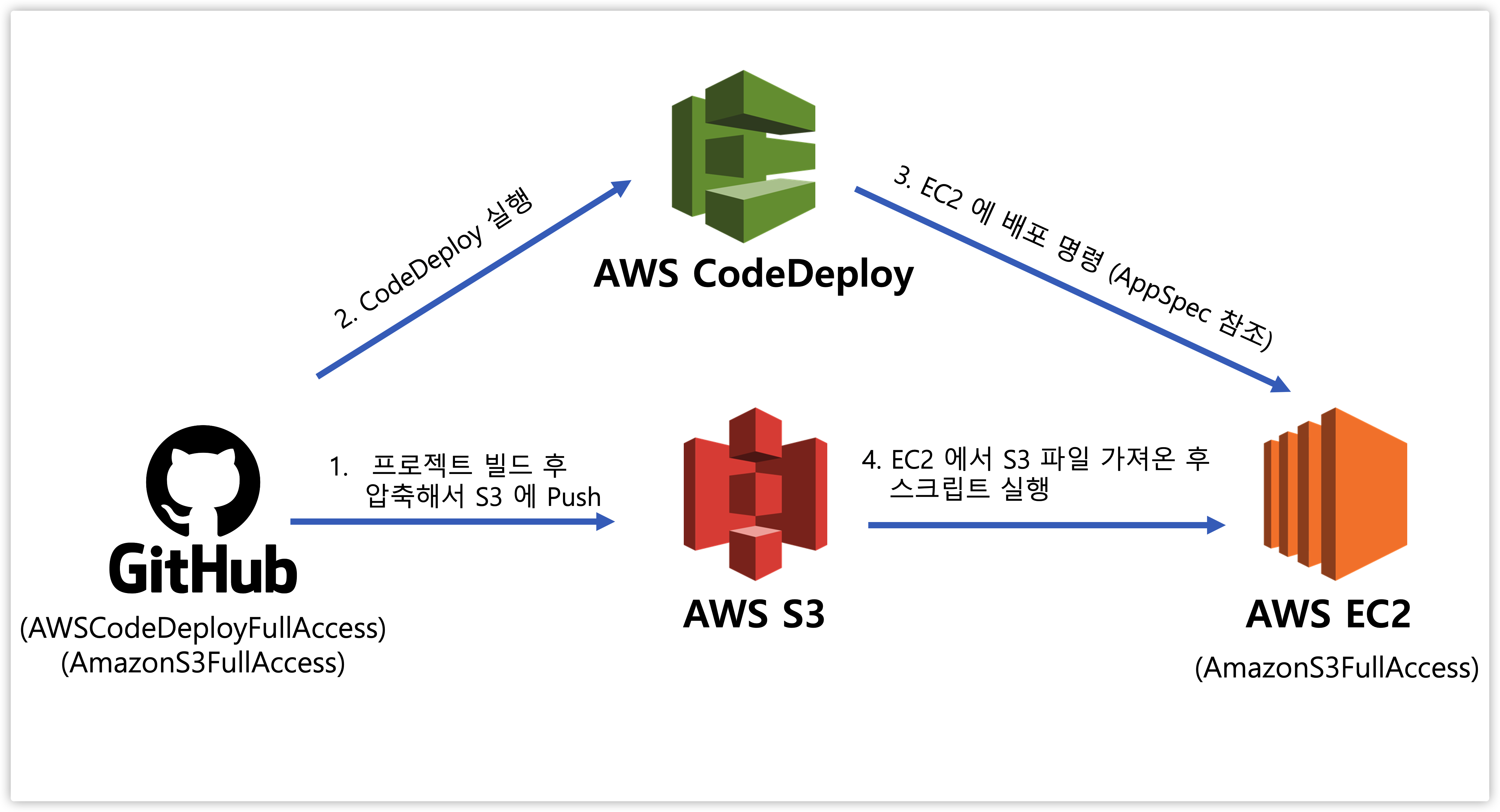
큰 흐름을 요약하면 다음과 같습니다.
- Github Actions 에서 코드 빌드 (테스트는 CI 에서 했다고 검증했다고 판단하여 생략)
- AWS 인증
- 코드 압축해서 AWS S3 에 업로드
- AWS CodeDeploy 실행하여 S3 에 있는 코드 EC2 에 배포
결국 Github 프로젝트 코드를 AWS S3 에 업로드 한 후 AWS EC2 에서 끌어다 쓰는 것이 가장 핵심이며 AWS CodeDeploy 는 그걸 보조해주는 역할을 담당합니다.
Github 에서 CodeDeploy, S3 에 접근하기 위한 권한이 필요하고 EC2 에서 S3 에 접근하기 위한 권한도 필요하기 때문에 설정이 조금 복잡하게 느껴질 수도 있습니다.
차근차근 진행 해보겠습니다.
2. EC2 설정 추가
AWS EC2 편 에서 생성한 인스턴스를 기준으로 아래 작업들을 추가로 진행합니다.
- Tag 추가 (CodeDeploy 에서 어떤 인스턴스에 실행할 지 구분하는 값)
- IAM 역할 등록
- EC2 서버에 CodeDeploy Agent 설치
2.1. Tag 추가
CodeDeploy 를 생성할 때 어떤 인스턴스에서 수행할 지 구분하는 값으로 태그를 사용하기 때문에 추가가 필요합니다.
기존에 인스턴스 생성할 때 태그까지 같이 생성했다면 이 과정은 생략해도 괜찮습니다.
2.1.1. EC2 설정에서 태그 관리 선택
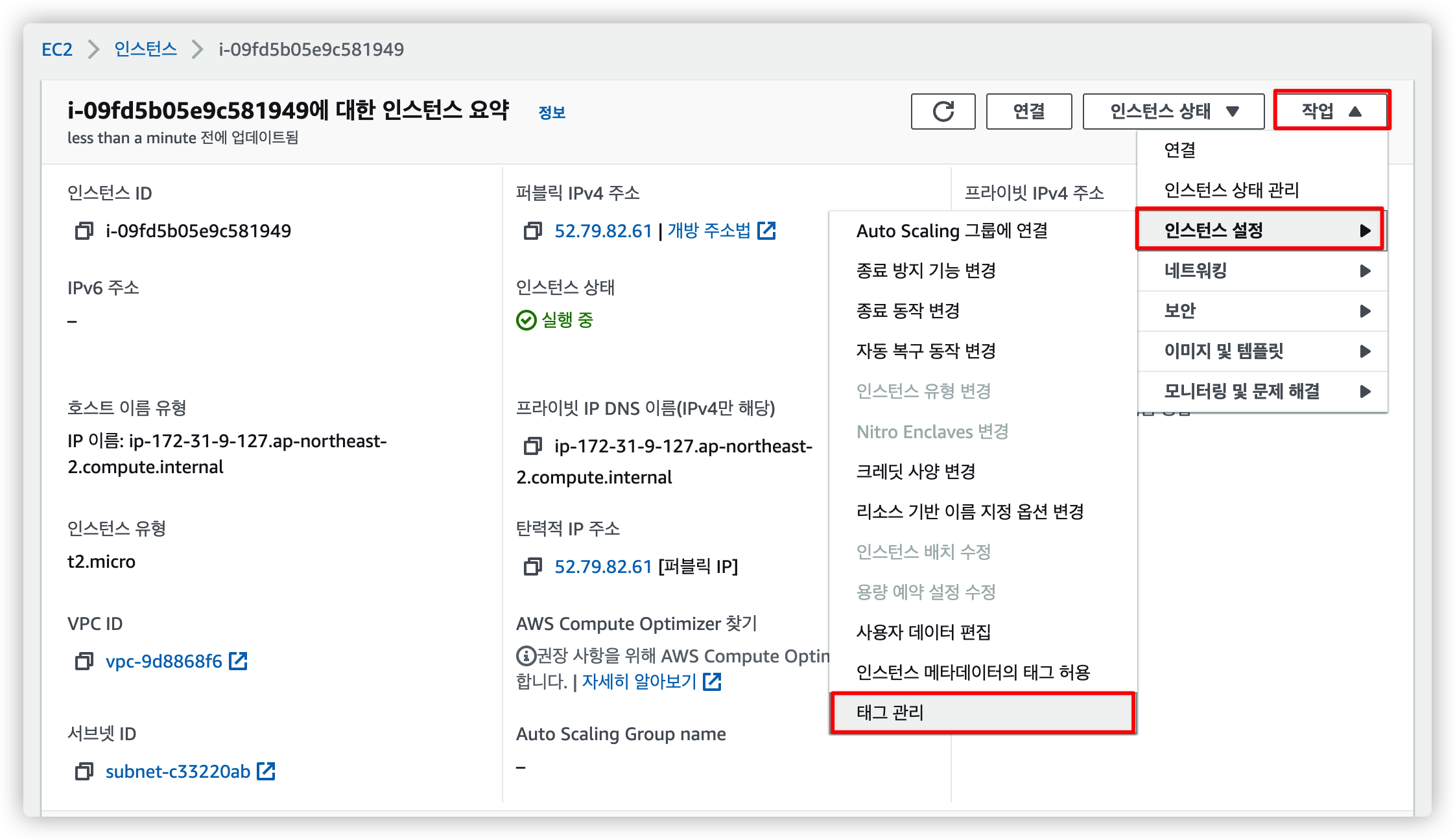
EC2 인스턴스 정보에 들어가 태그 관리를 선택합니다.
2.1.2. 태그 추가
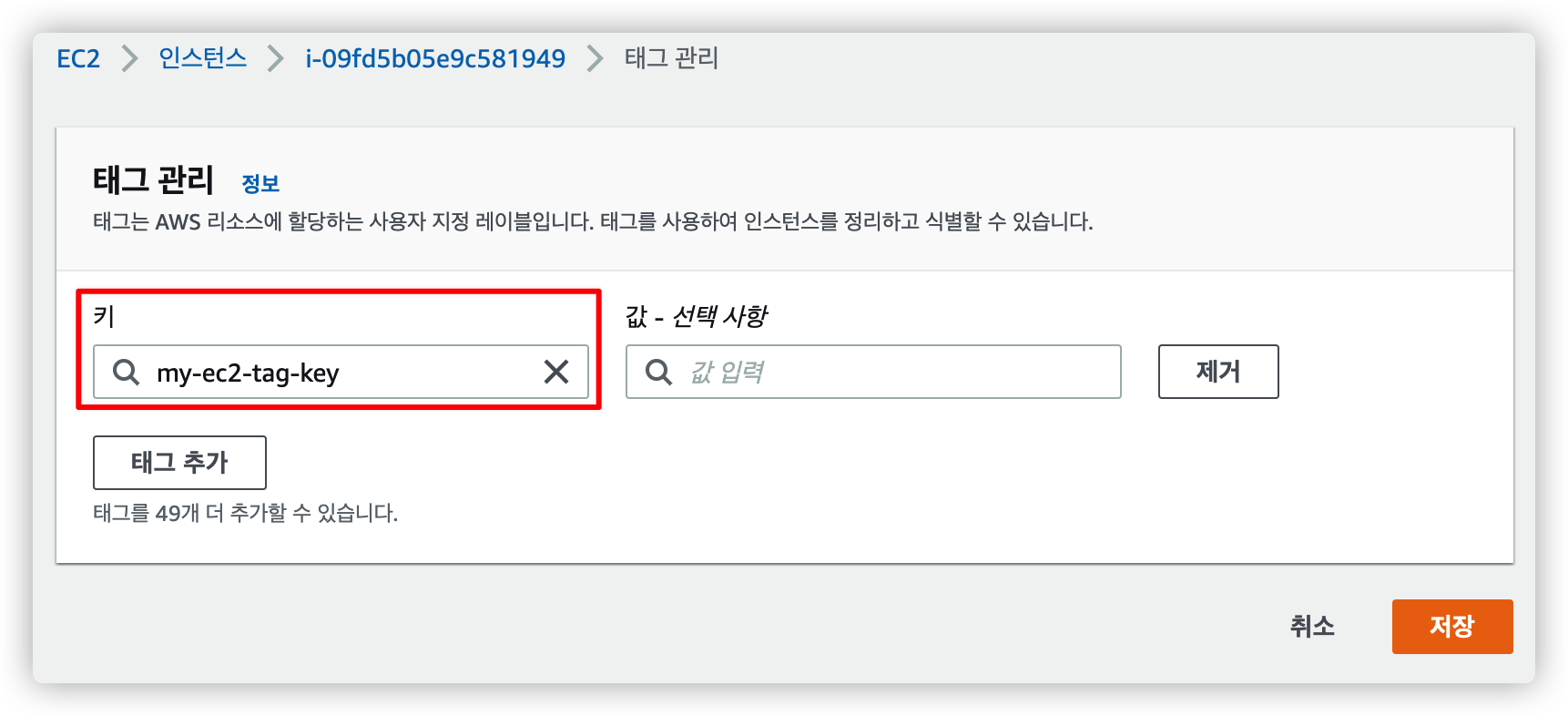
원하는 키 값을 입력하고 저장을 누릅니다.
2.1.3. 태그 확인
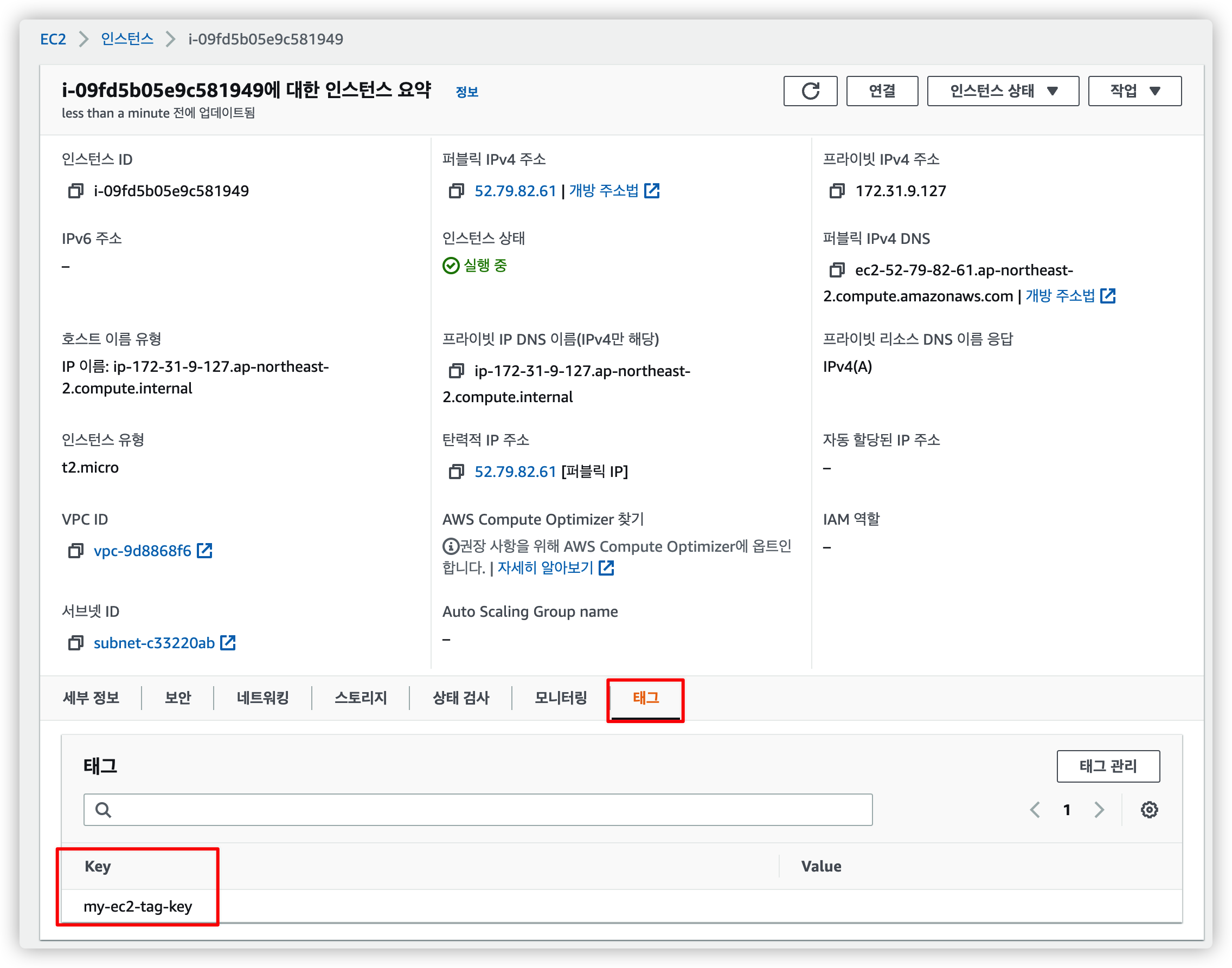
다시 EC2 인스턴스 정보에서 태그가 등록되었는지 확인할 수 있습니다.
2.2. IAM 역할 추가
EC2 인스턴스에서 S3 에 올려놓은 파일에 접근할 수 있도록 권한을 추가해줘야 합니다.
2.2.1. IAM 역할 관리 페이지로 이동
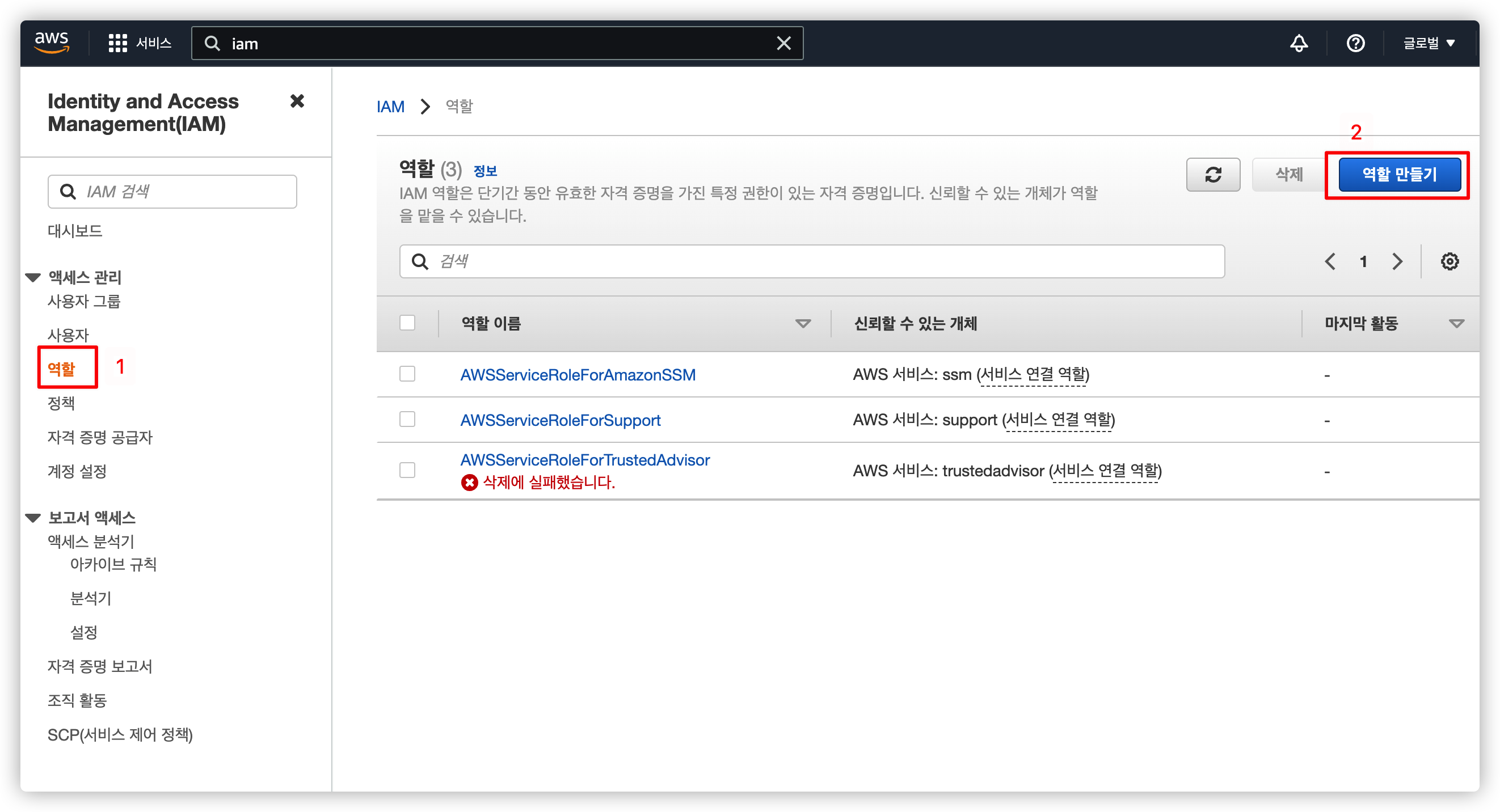
기본적으로 존재하는 역할들이 있는데 신경쓰지 말고 새로운 역할 만들기를 선택합니다.
2.2.2. EC2 엔티티 선택
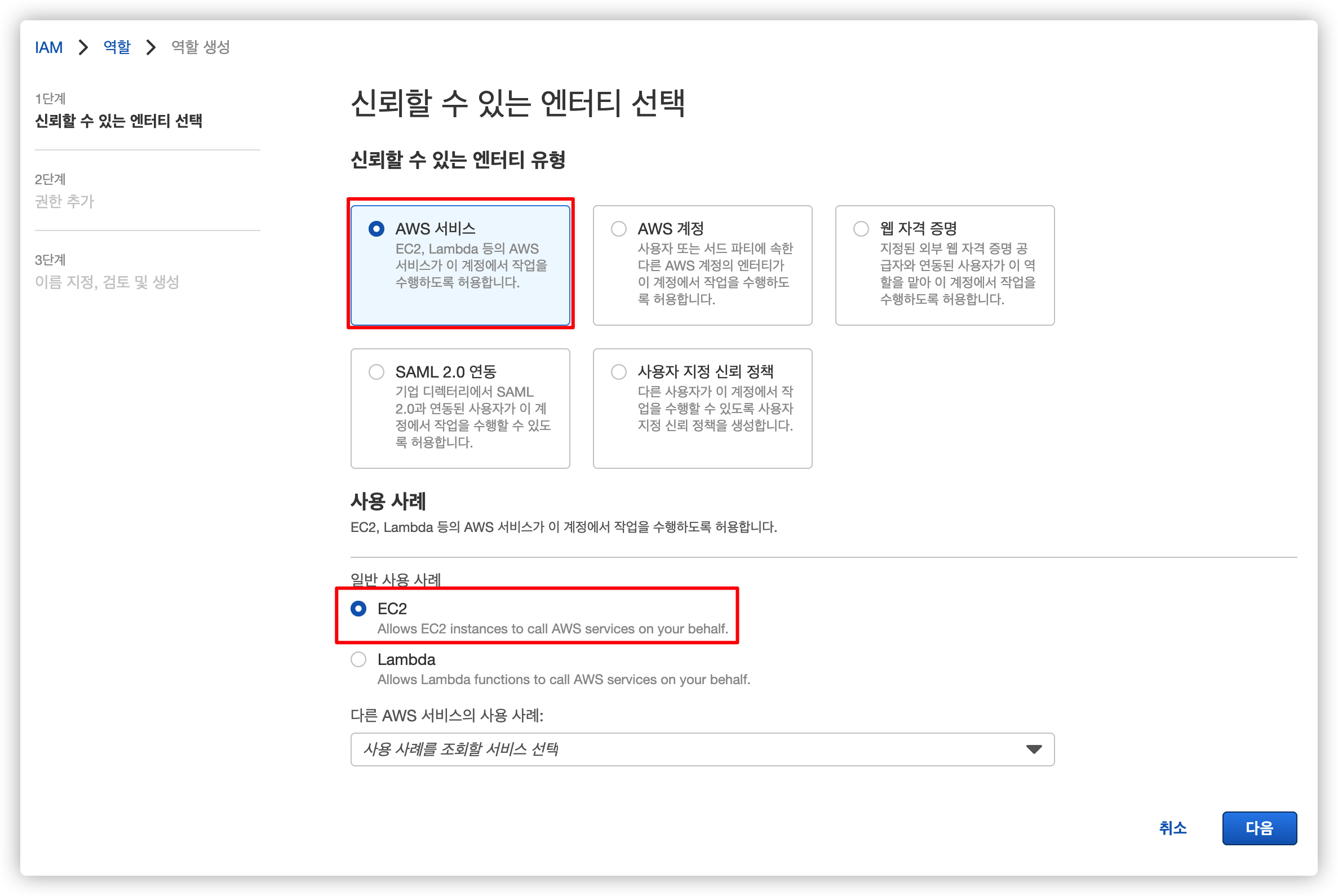
IAM 역할을 연결할 서비스를 선택합니다.
2.2.3. S3 접근 권한 추가
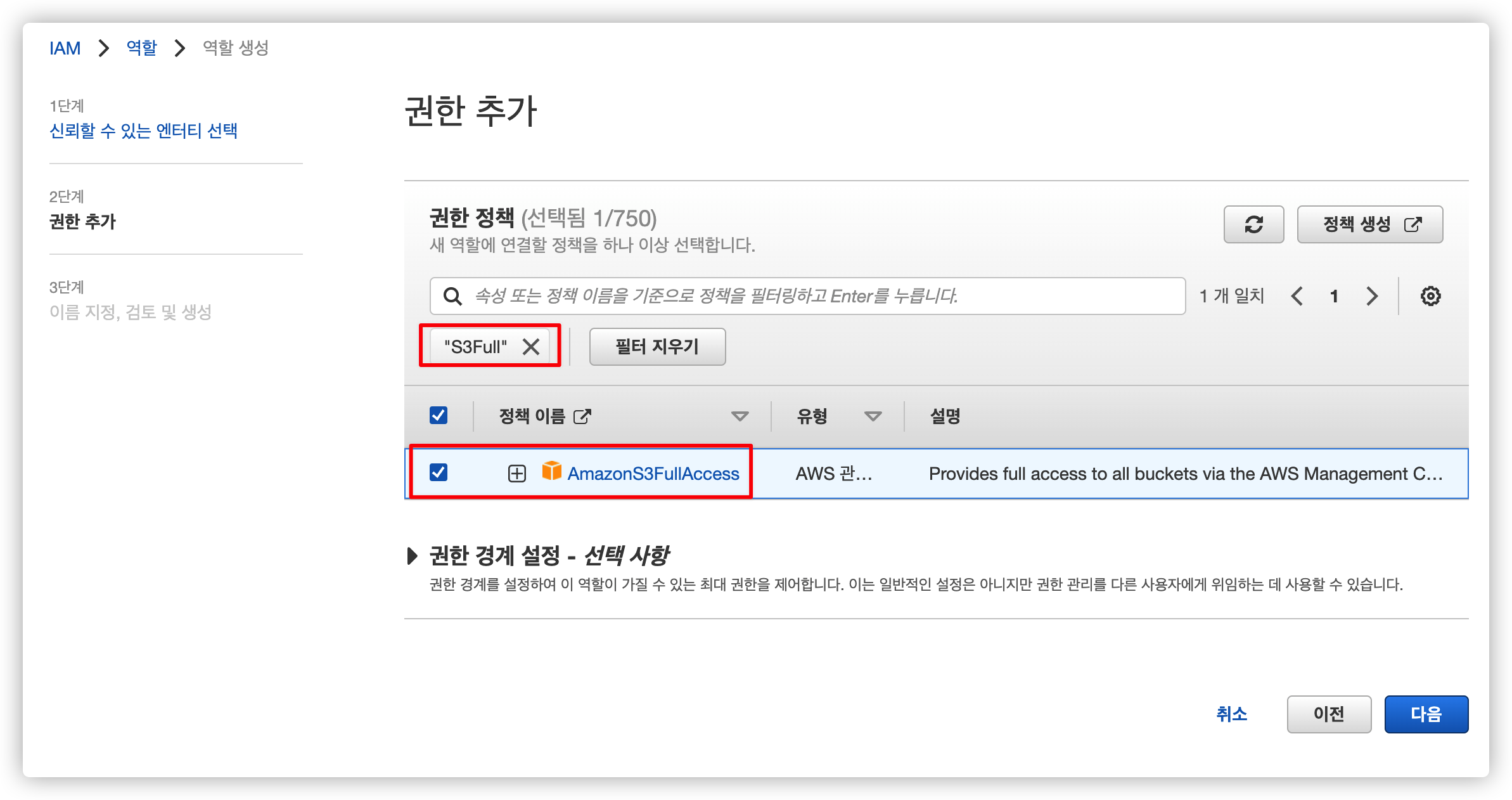
EC2 인스턴스에서 S3 접근할 수 있도록 AmazonS3FullAccess 권한을 추가합니다.
2.2.4. 이름 설정
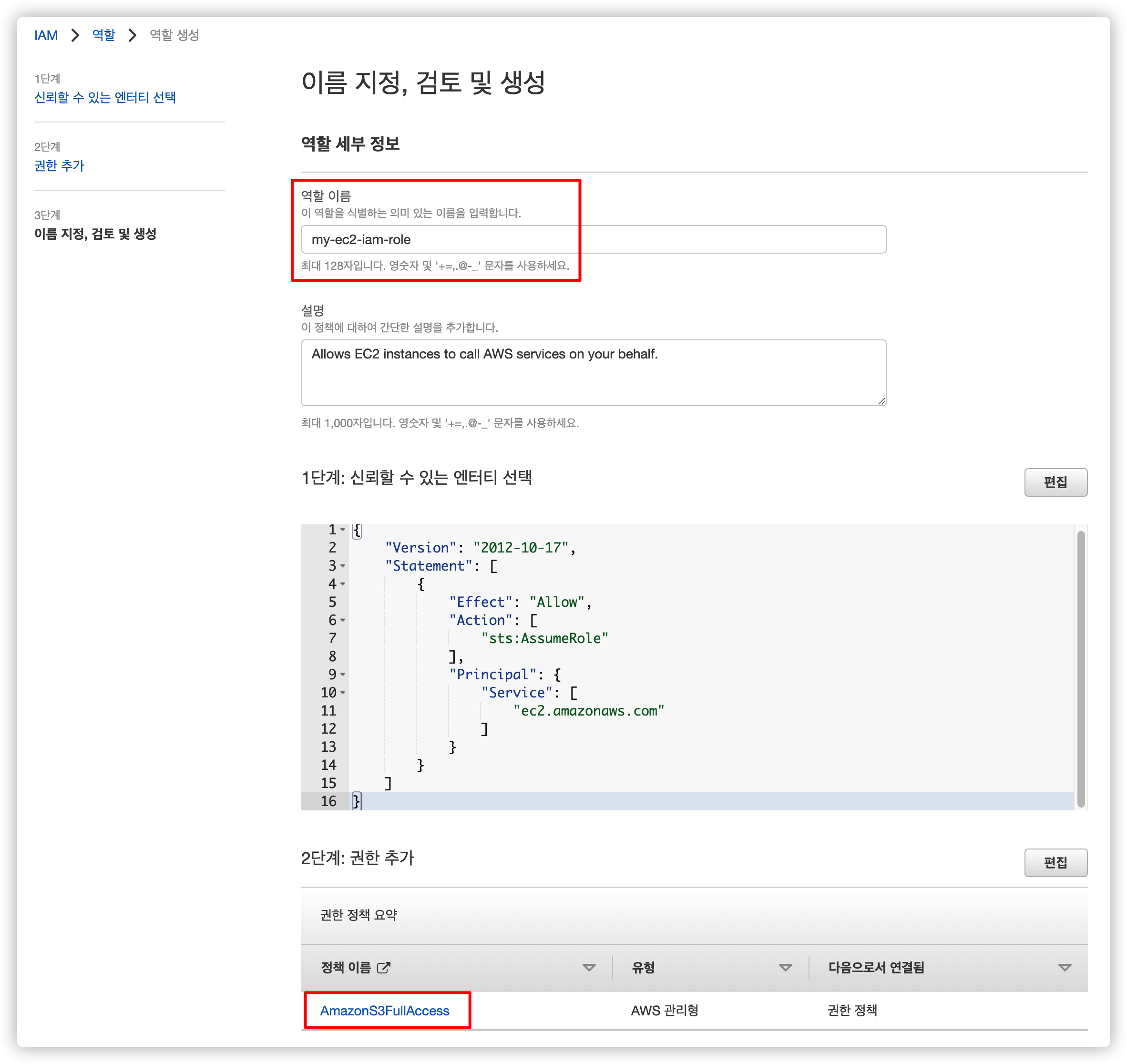
마지막으로 원하는 이름을 입력한 뒤 생성을 완료합니다.
2.2.5. EC2 인스턴스에서 IAM 연결
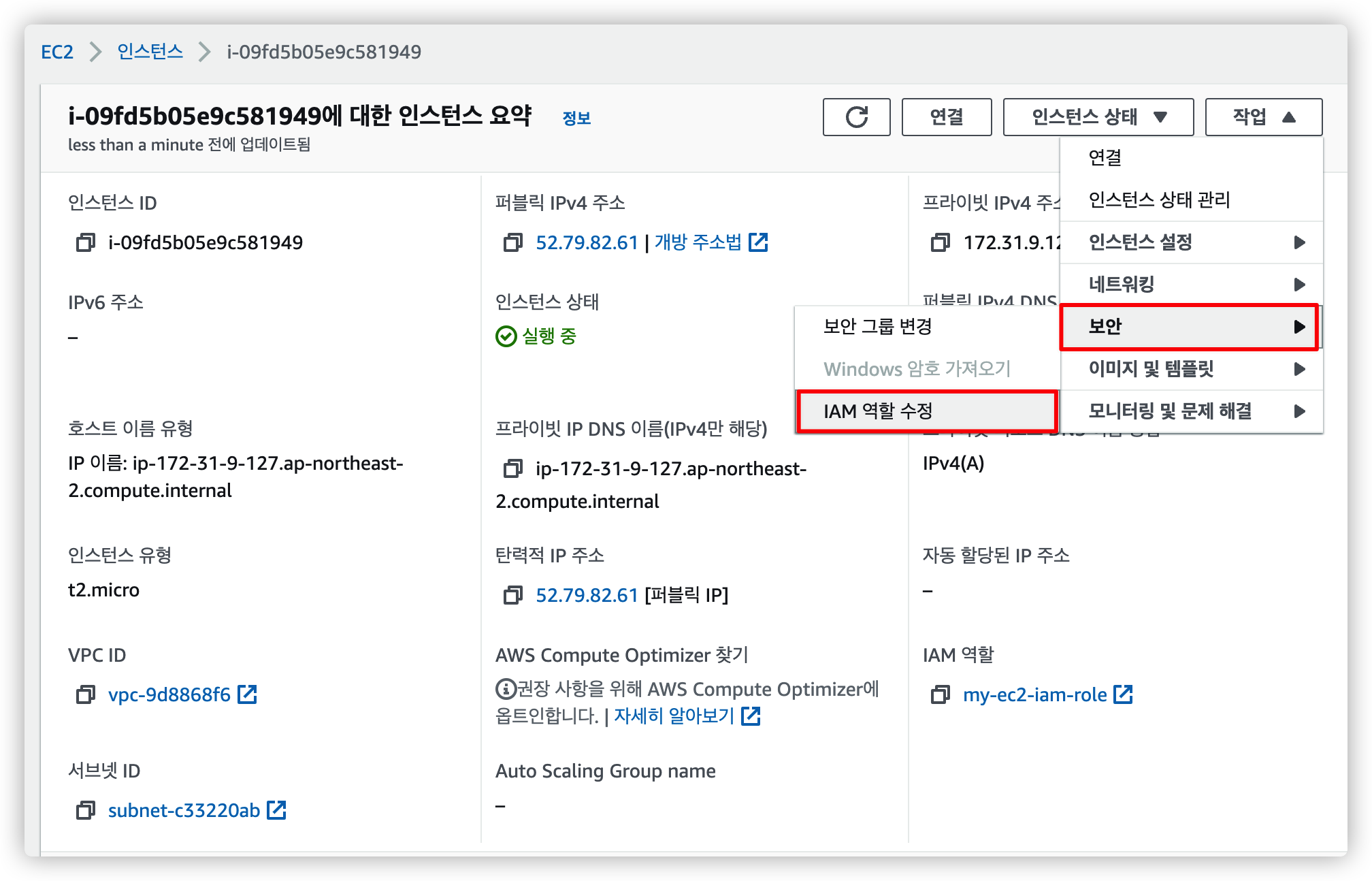
EC2 인스턴스 관리 페이지로 이동해서 "작업 > 보안 > IAM 역할 수정" 을 선택합니다.
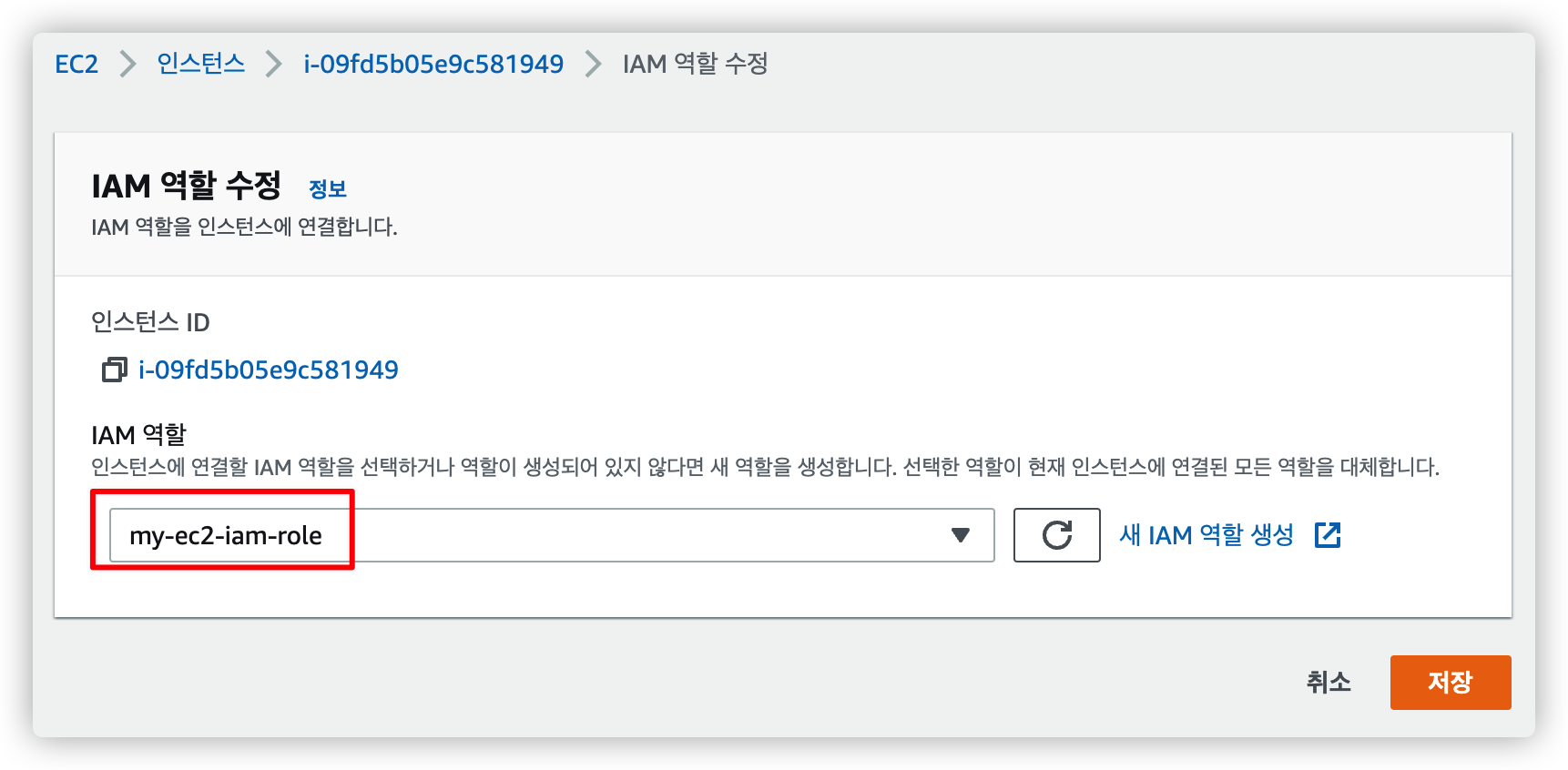
방금 만든 EC2 전용 IAM 역할을 선택한 뒤 저장을 누르면 연결이 완료됩니다.
2.3. CodeDeploy Agent 설치
$ sudo apt update
$ sudo apt install ruby-full
$ sudo apt install wget
$ cd /home/ubuntu
$ wget https://aws-codedeploy-ap-northeast-2.s3.ap-northeast-2.amazonaws.com/latest/install
$ chmod +x ./install
$ sudo ./install auto > /tmp/logfile
$ sudo service codedeploy-agent status
CodeDeploy Agent 설치 를 보고 명령어를 따라 치기만 하면 됩니다.
EC2 환경이 Ubuntu 가 아니거나 버전이 다르다면 공식 문서를 참고해주세요.
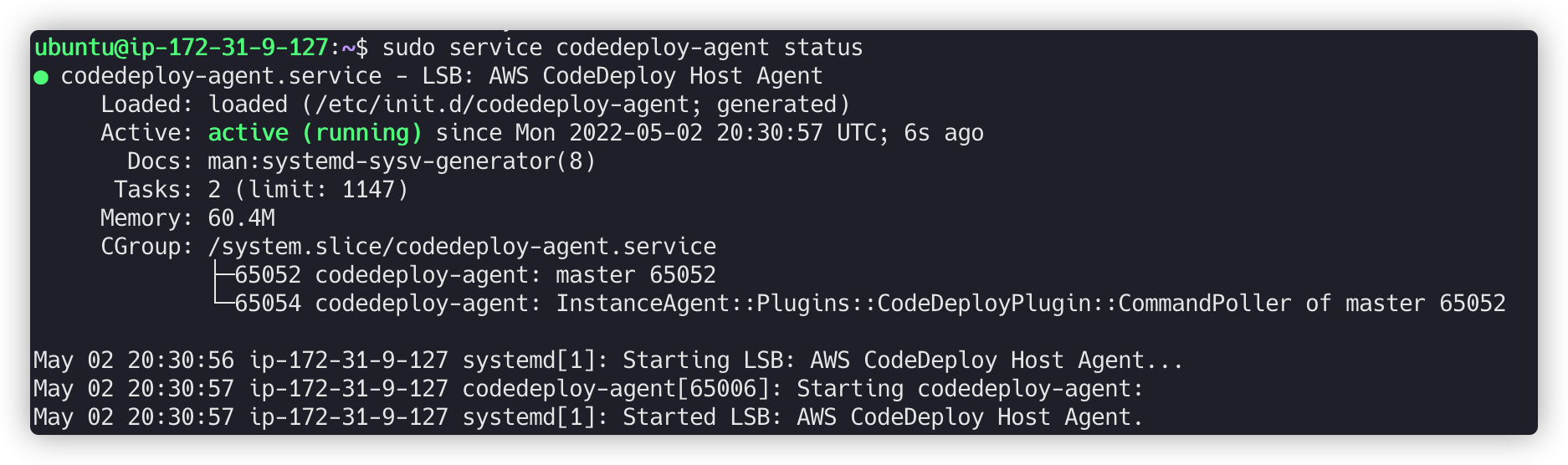
정상적으로 설치가 완료되면 이런 응답이 와야 합니다.
3. AWS S3 생성
AWS S3 버킷이란 이미지 또는 zip 파일을 저장하기 위한 스토리지 서비스입니다.
빌드한 프로젝트 코드를 압축해서 S3 에 저장한 후 EC2 서버에서 S3 에 접근해서 압축한 파일을 가져오기 위해 사용합니다.
3.1. S3 메뉴에서 버킷 생성
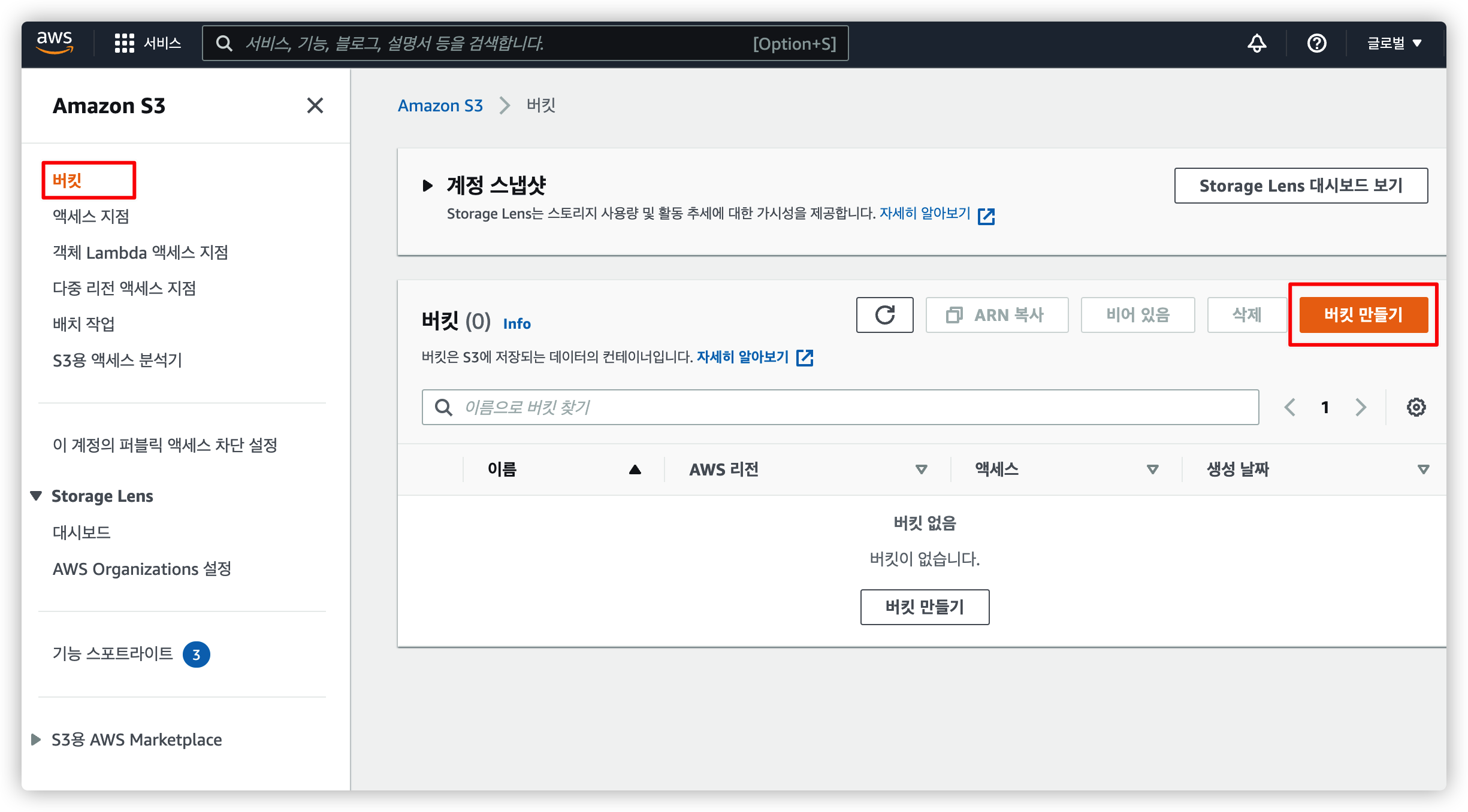
S3 메뉴로 이동해서 "버킷 만들기" 를 누릅니다.
3.2. 일반 구성과 객체 소유권 설정
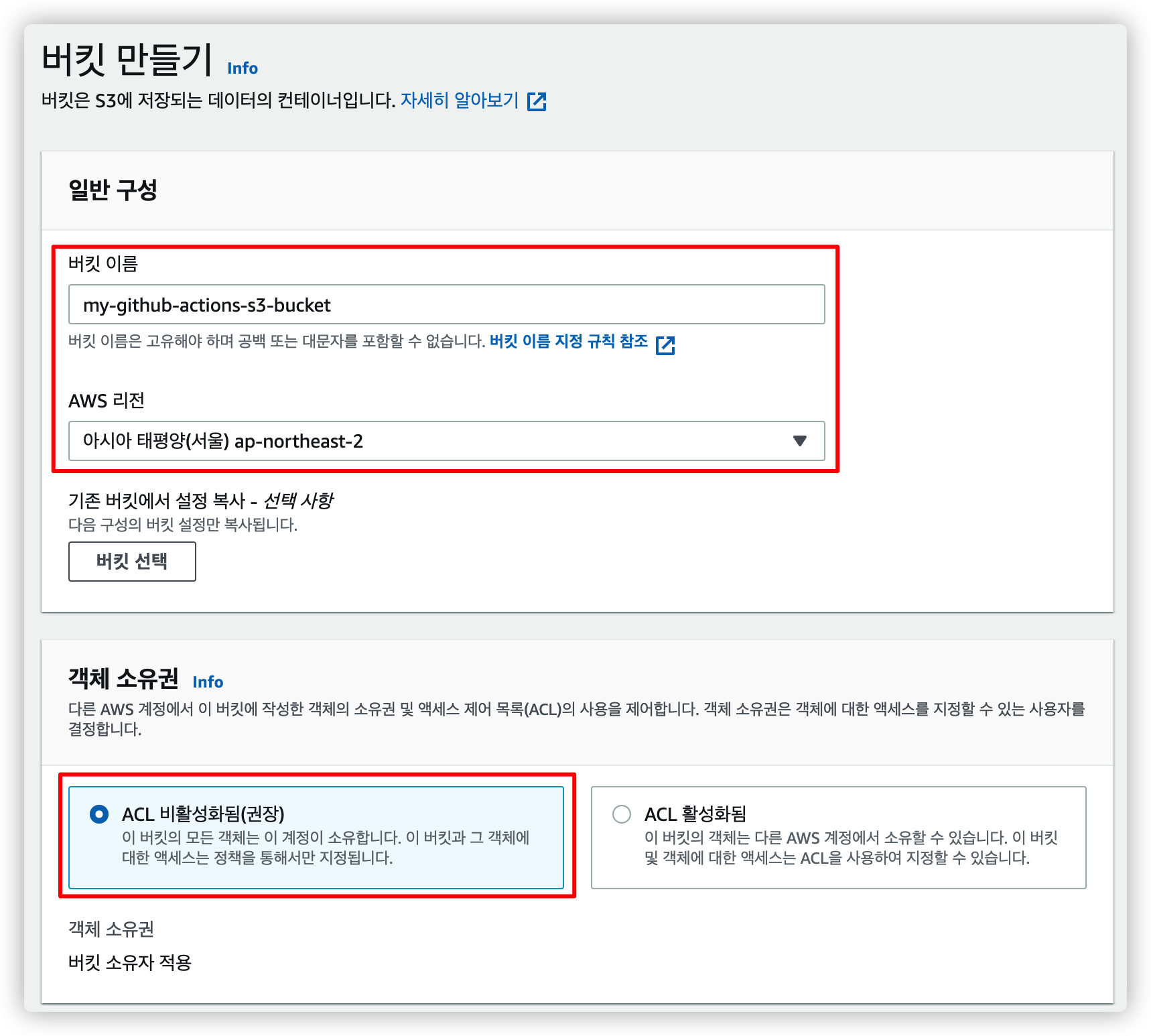
원하는 버킷 이름과 리전을 선택합니다.
ACL 은 기본값을 선택해서 비활성화 합니다.
3.3. 액세스, 버킷 버전, 암호화 비활성화
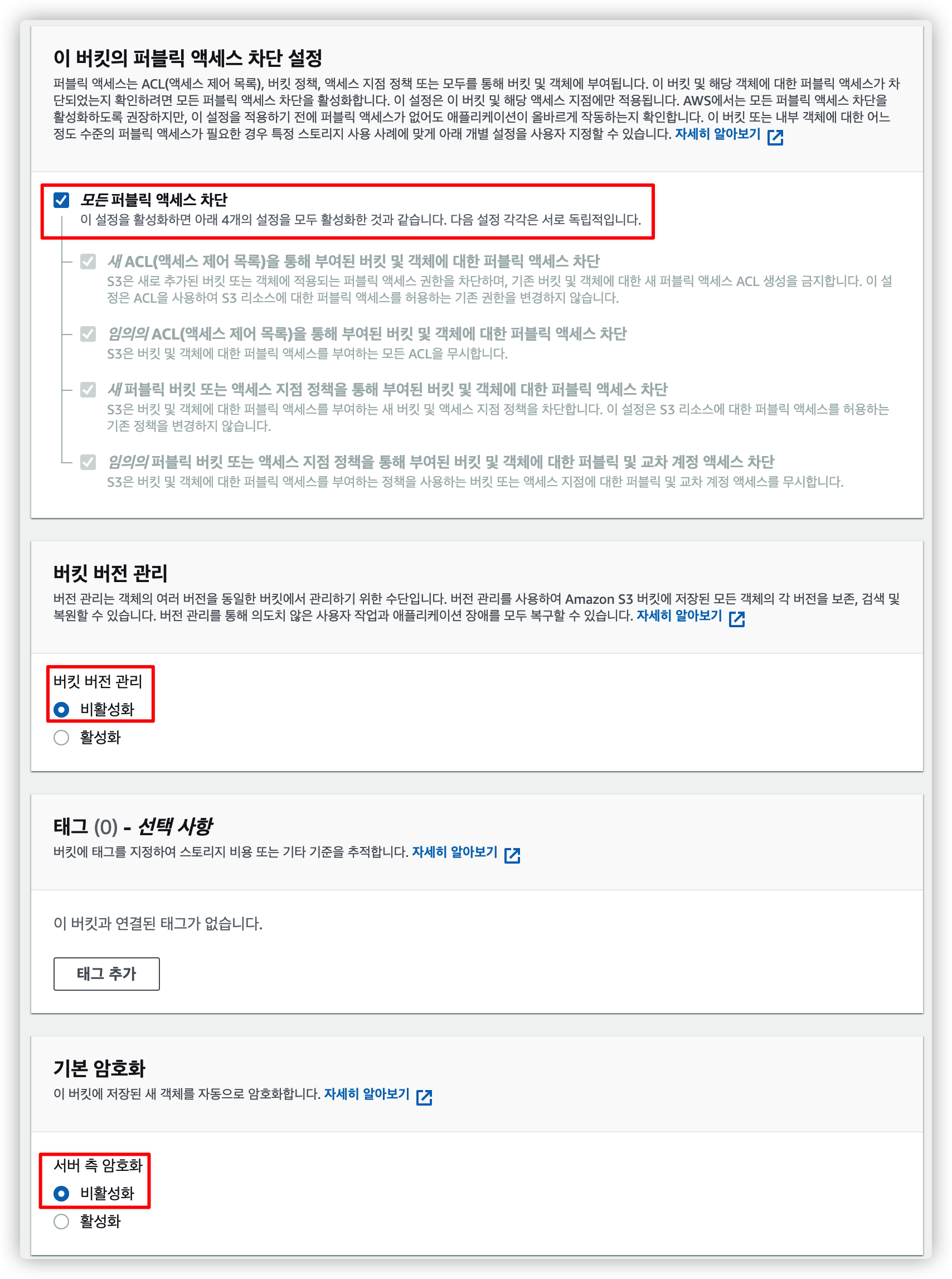
나머지 설정을 마저 합니다.
변경할 필요 없이 기본값 그대로 두면 됩니다.
3.4. S3 버킷 생성 완료
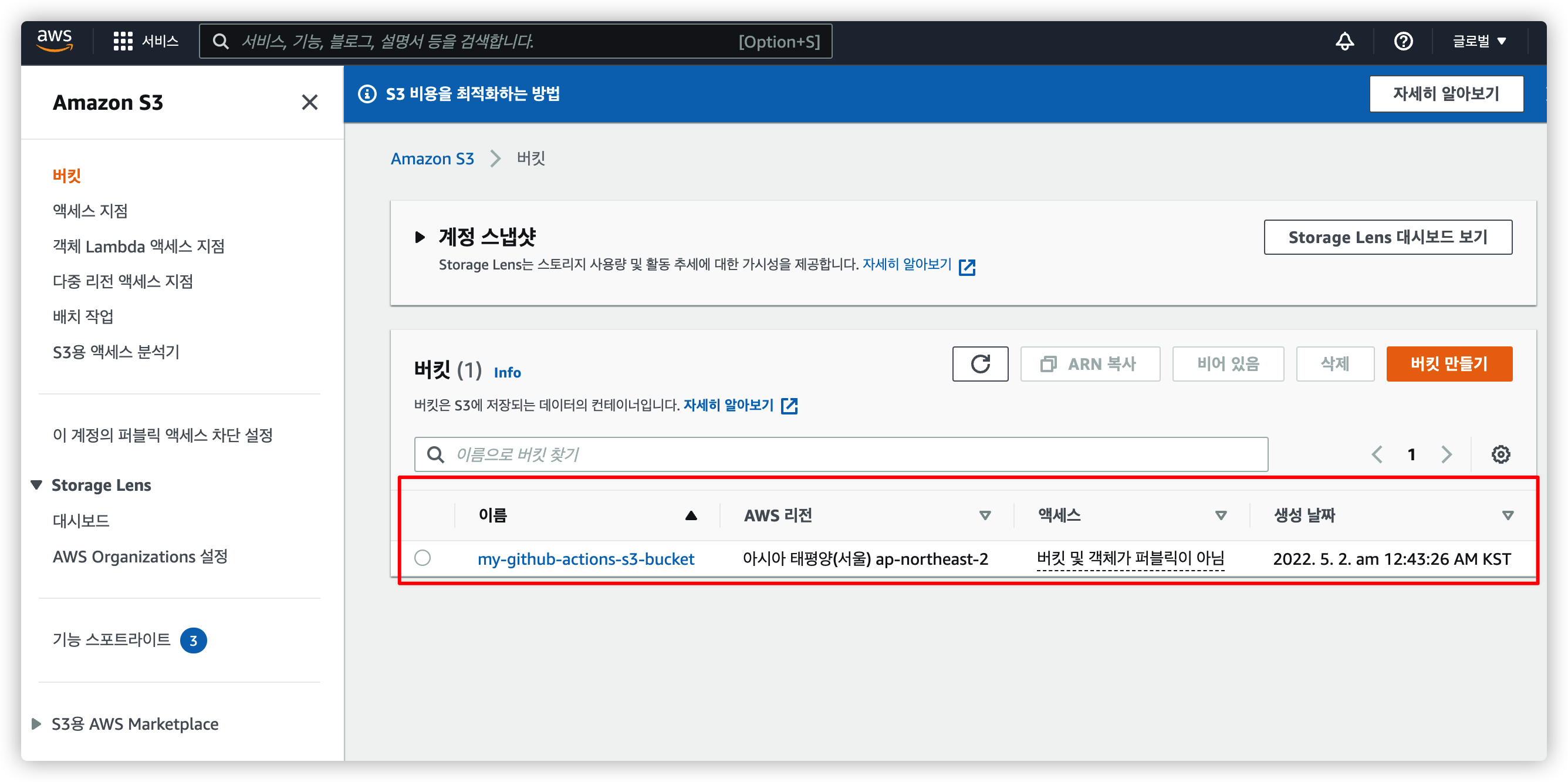
버킷 생성이 완료되면 이렇게 나타납니다.
4. CodeDeploy 생성
배포를 도와주는 CodeDeploy 생성 및 설정을 진행해봅니다.
4.1. CodeDeploy 전용 IAM 역할 만들기
CodeDeploy 를 사용하기 위해선 IAM 에서 역할을 만들어야 합니다.
4.1.1. IAM 메뉴에서 역할 선택
IAM 서비스로 이동해서 역할 만들기를 선택합니다.
4.1.2. CodeDeploy 엔티티 선택
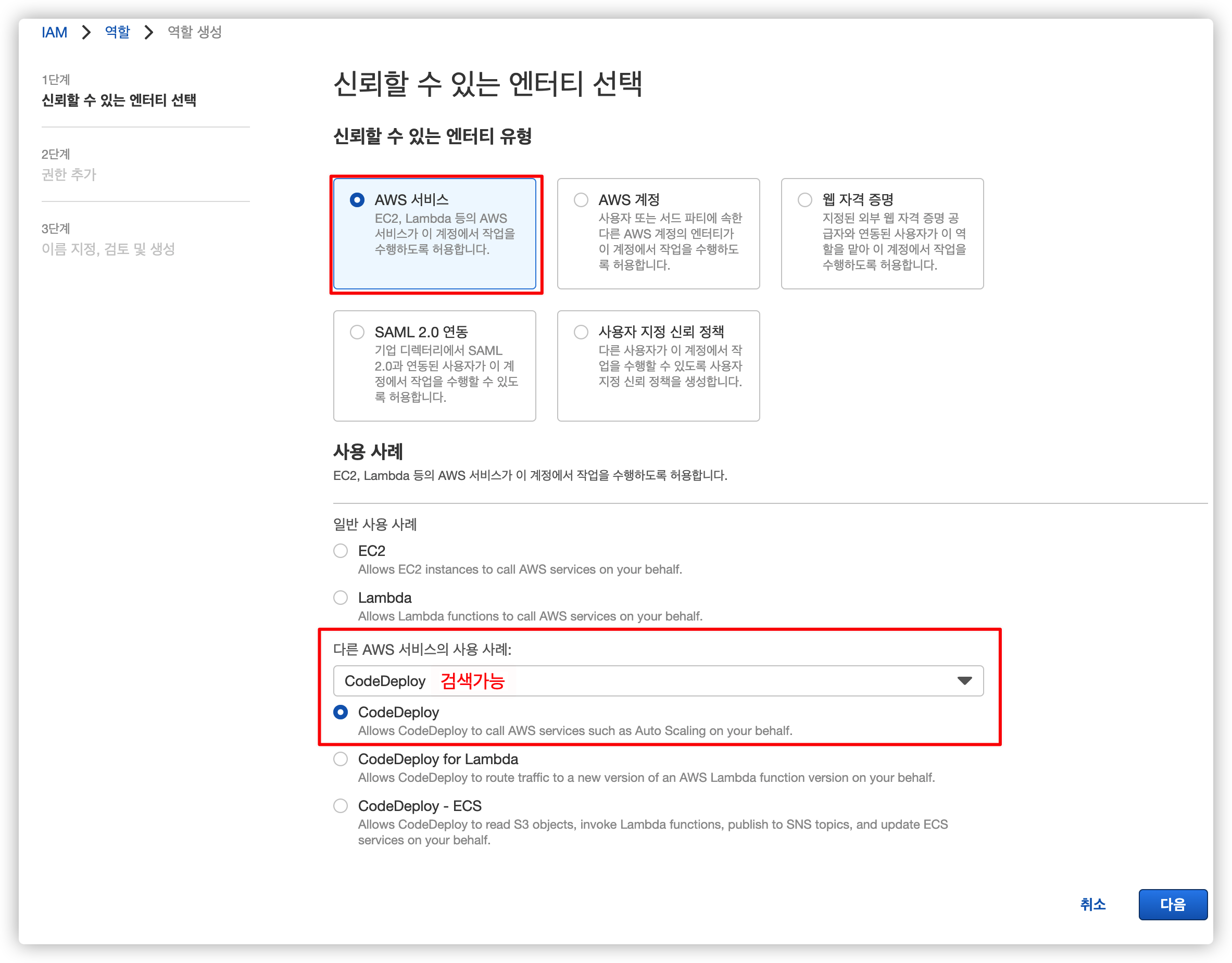
기본적으로 제공되는 AWS 서비스에서 CodeDeploy 를 검색한 후 가장 기본적인 걸 선택합니다.
4.1.3. IAM 이름 설정
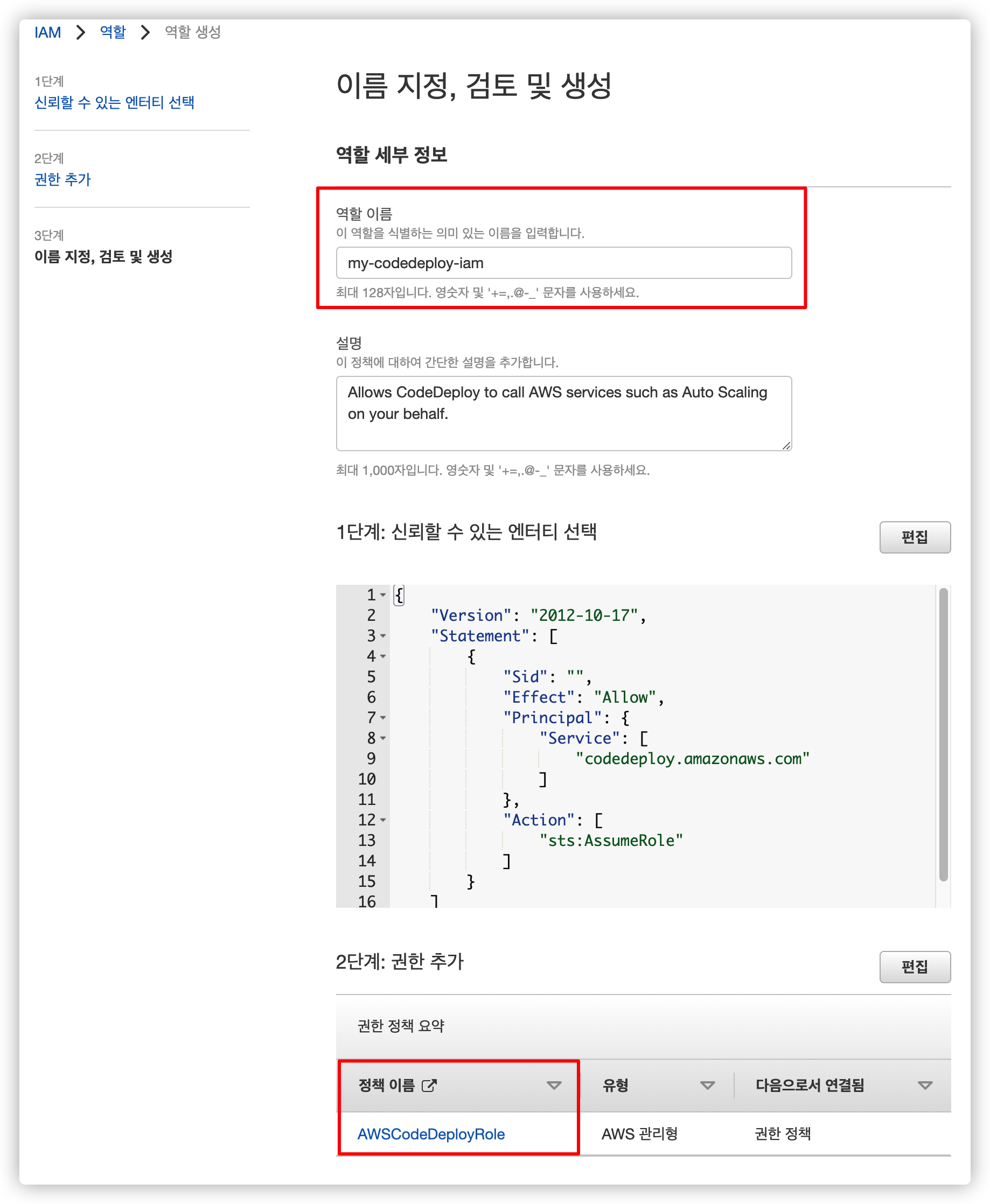
나머지는 건들 필요 없고 이름만 새로 추가합니다.
저는 my-codedeploy-iam 로 설정했습니다.
이름을 입력했다면 "역할 생성" 을 눌러 마무리합니다.
4.2. CodeDeploy 애플리케이션 생성
이제 우리가 사용할 CodeDeploy 앱을 생성합니다.
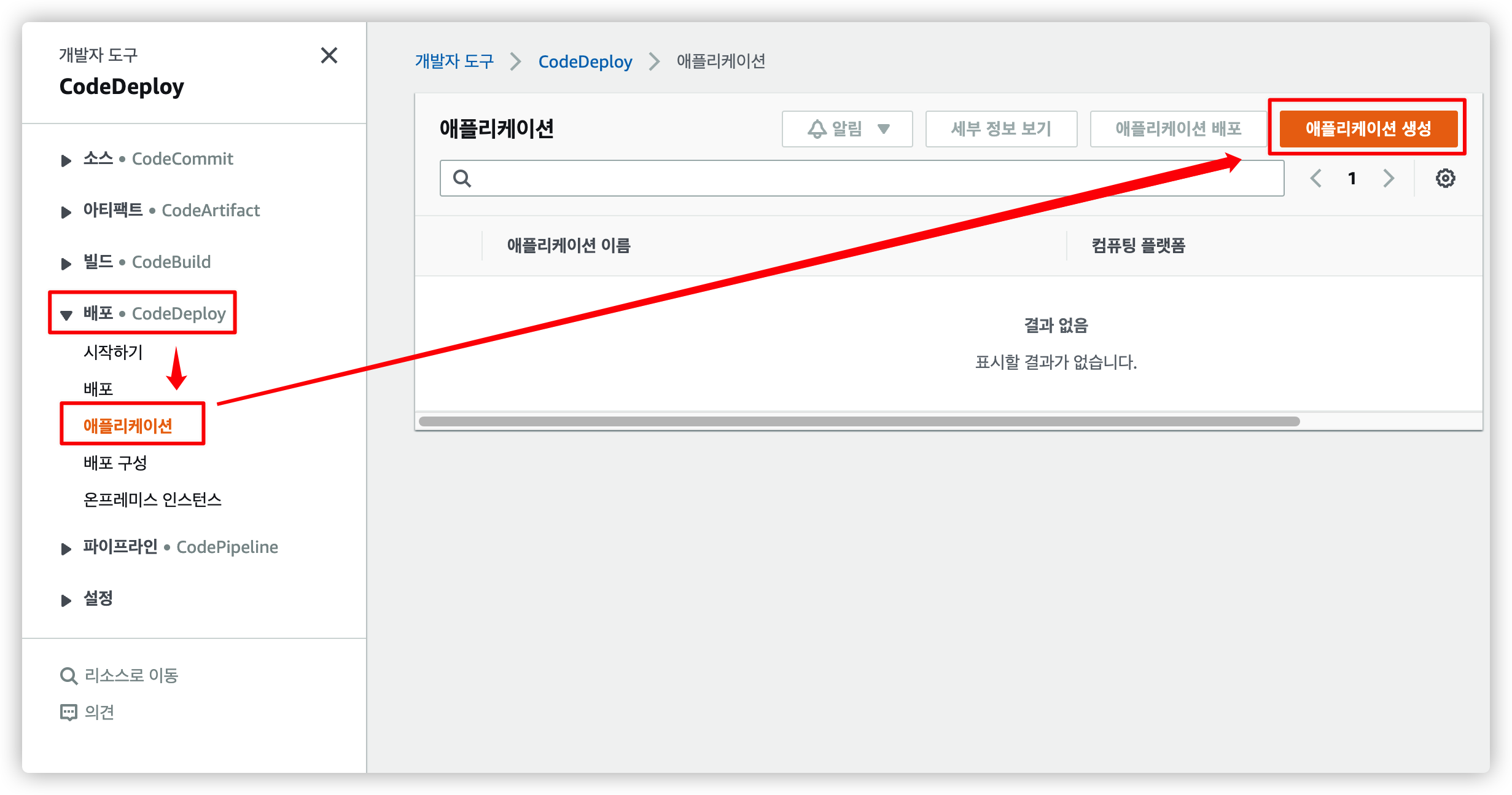
메뉴에서 생성 버튼을 누릅니다.
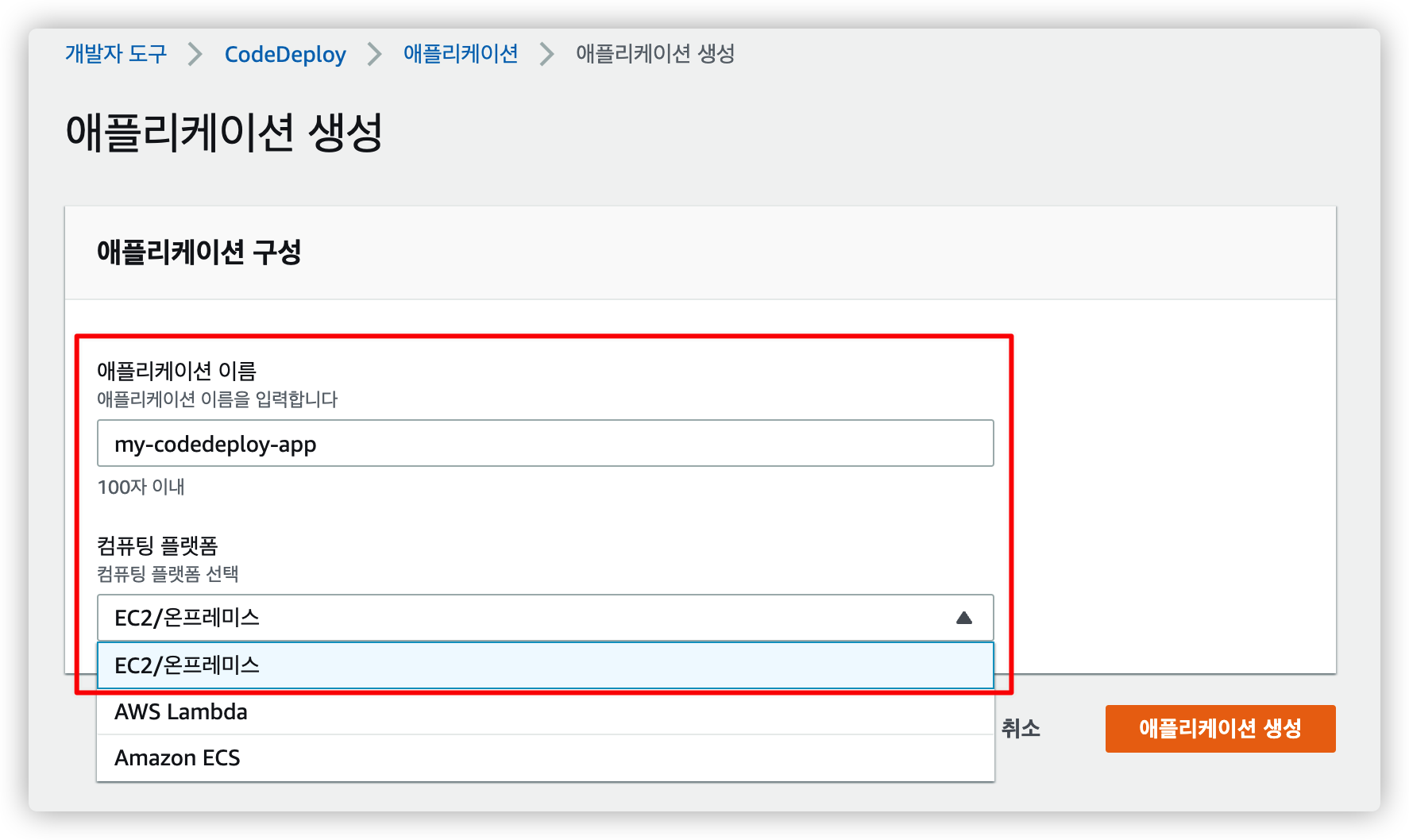
원하는 이름을 입력 후 컴퓨팅 플랫폼은 EC2/온프레미스 를 선택합니다.
4.3. CodeDeploy 배포 그룹 생성
CodeDeploy 애플리케이션에서 사용하는 배포 그룹을 생성합니다.
4.3.1. 메뉴에서 선택
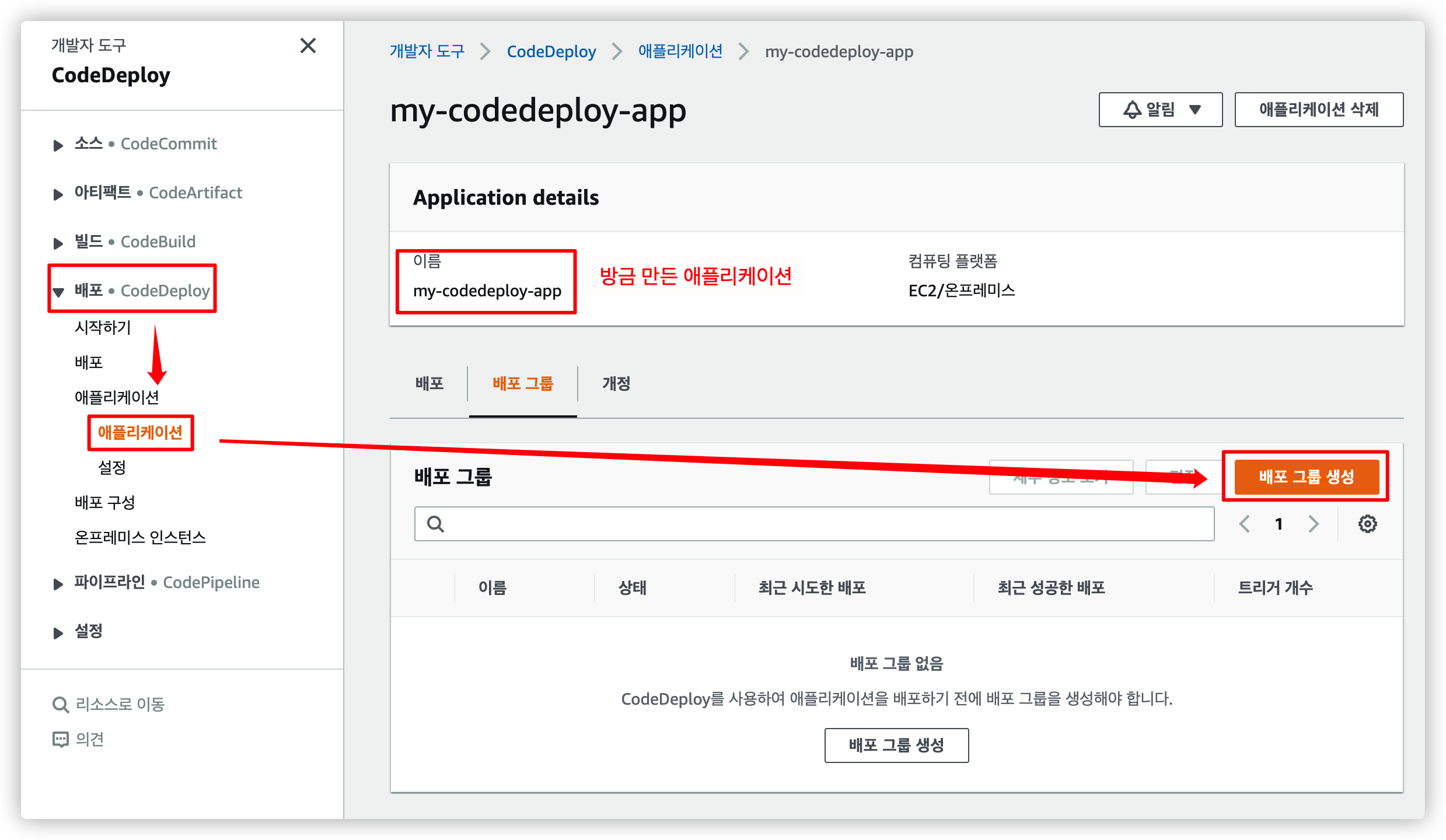
방금 만든 애플리케이션에서 배포 그룹 생성을 누릅니다.
4.3.2. 이름, 역할, 유형 선택
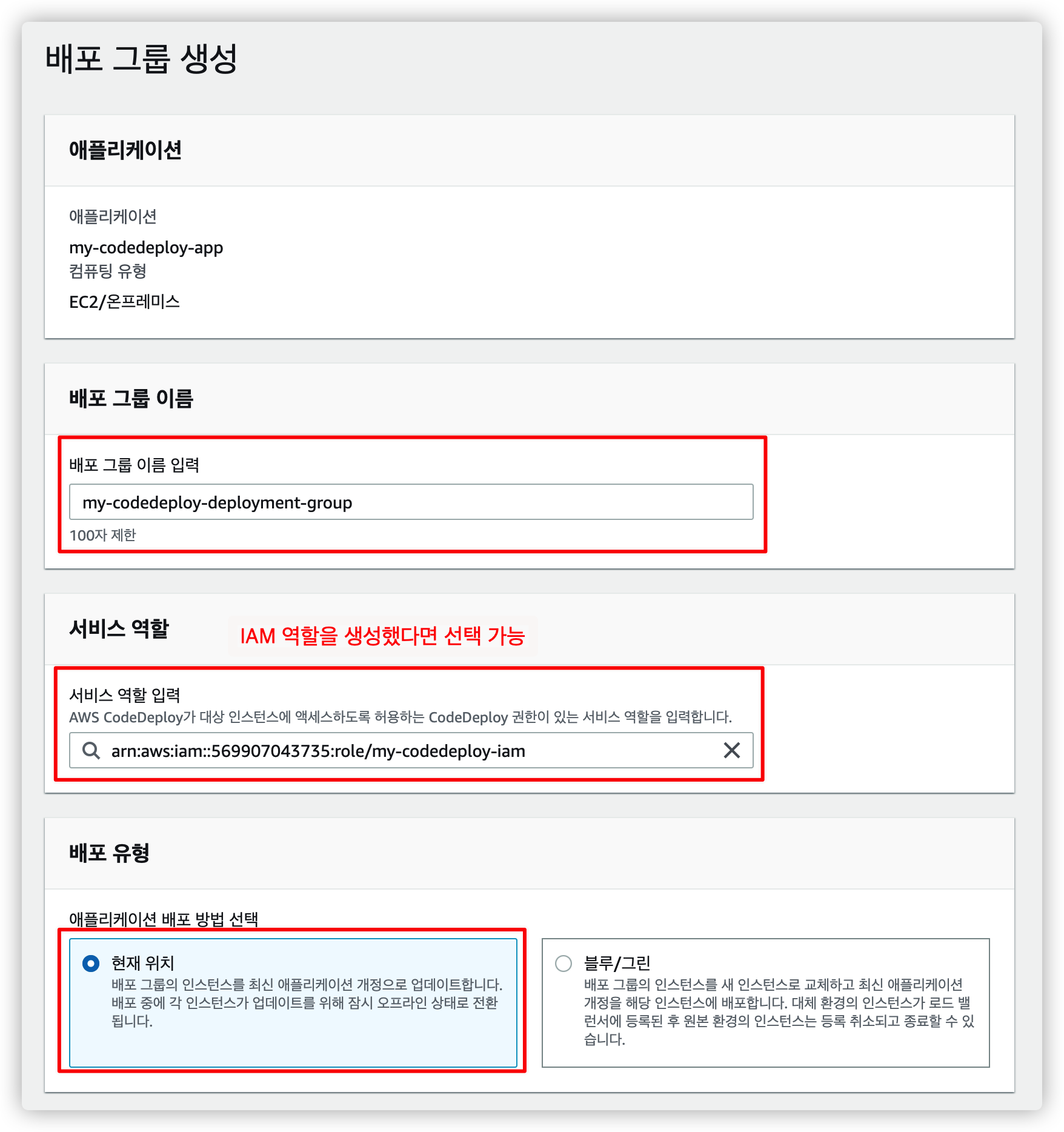
원하는 배포 그룹 이름, 역할, 유형을 설정합니다.
서비스 역할은 위에서 만든 IAM 역할을 선택할 수 있게 나옵니다.
4.3.3. EC2 인스턴스 선택
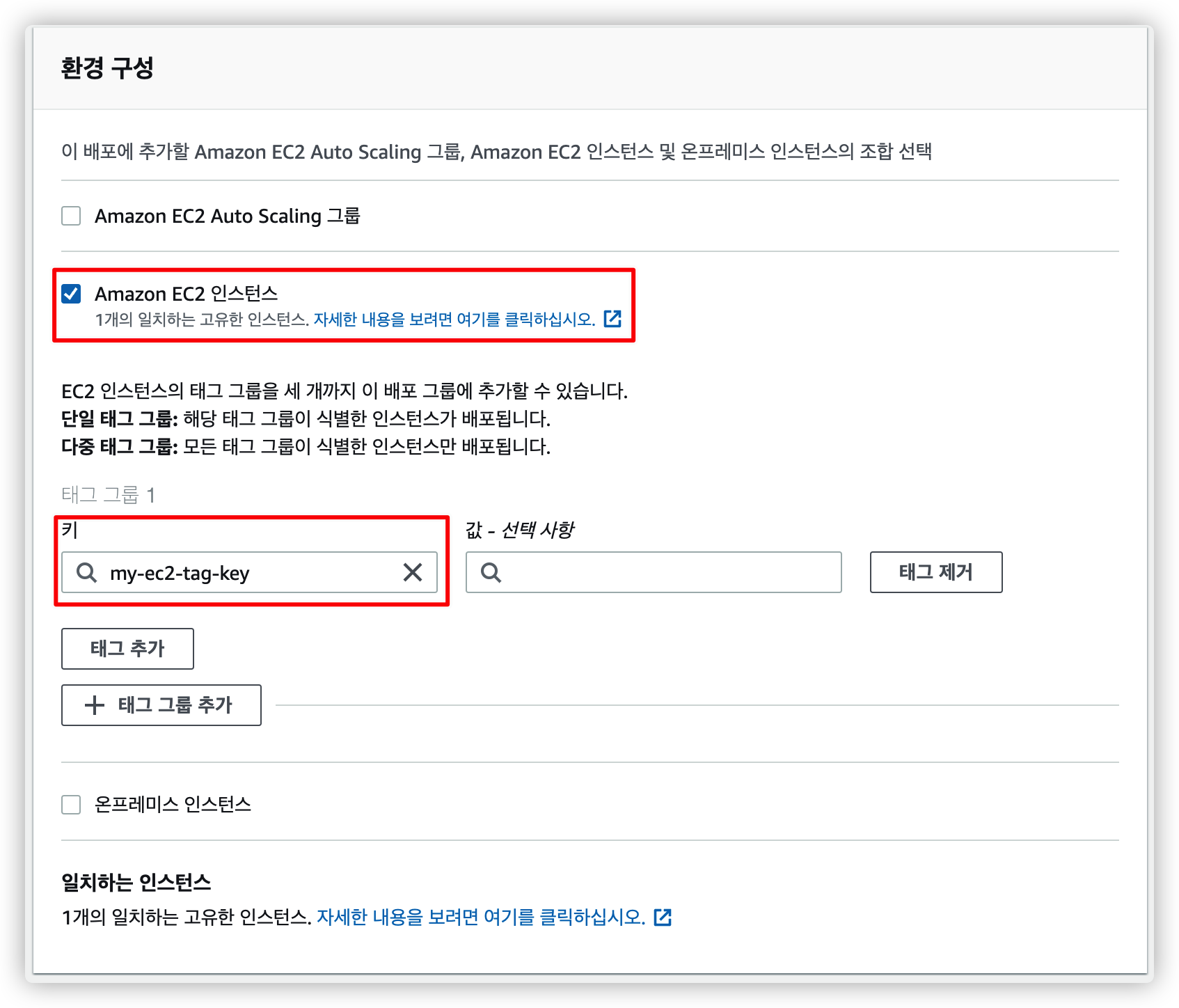
어떤 인스턴스에서 동작할 지 선택합니다.
EC2 인스턴스에서 태그를 추가해야 선택할 수 있습니다.
우리는 위에서 이미 기존 EC2 인스턴스에 태그를 추가했기 때문에 해당 태그 키를 선택합니다.
4.3.4. 나머지 설정 후 배포 그룹 생성
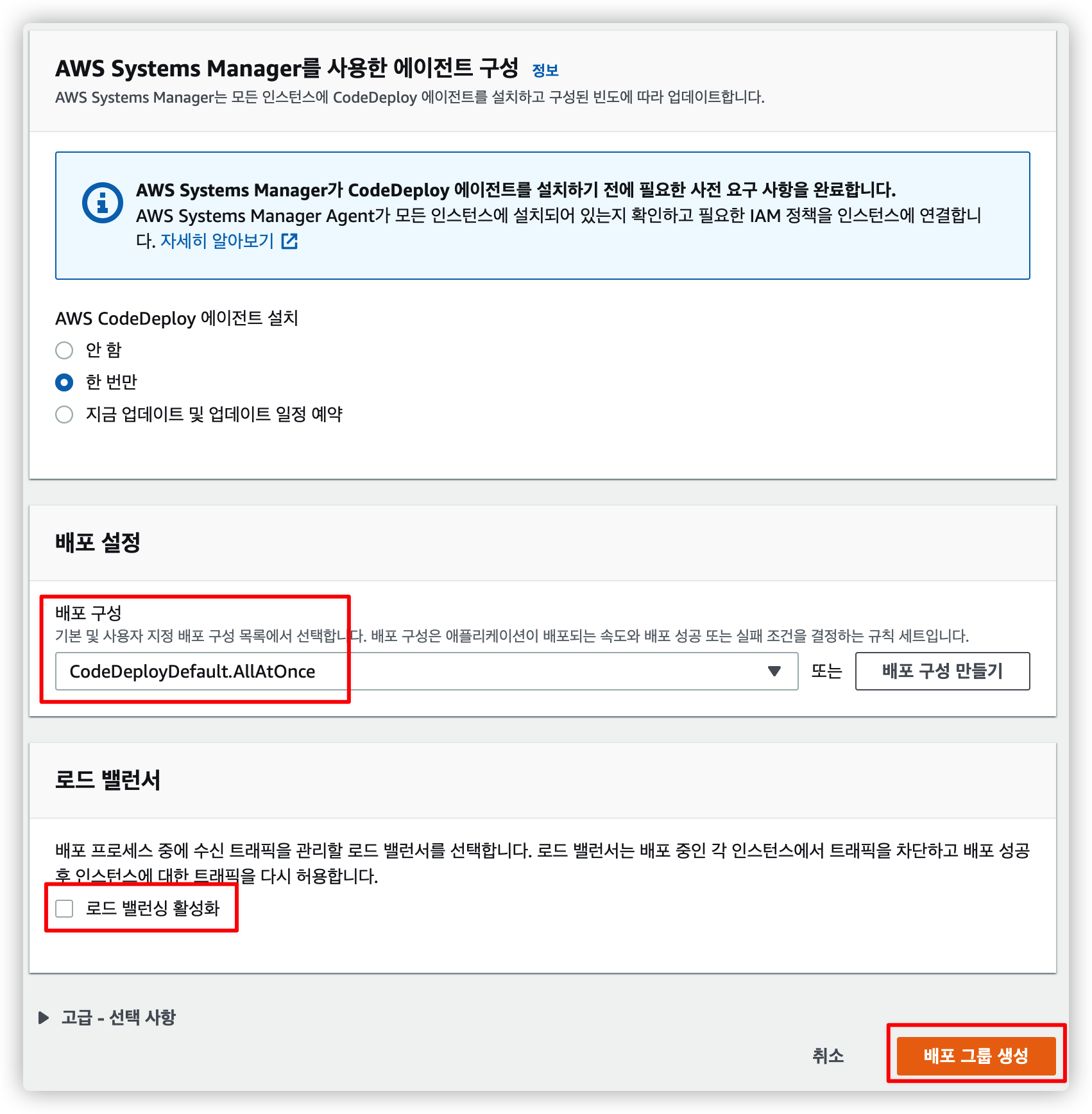
AWS Systems Manager 는 크게 중요한거 같지 않으니 적당히 선택하고 로드 밸런싱을 사용하지 않으니 체크만 해제합니다.
다 설정했으면 배포 그룹 생성을 눌러 마무리합니다.
5. Github Actions 에서 사용할 IAM 사용자 추가
AWS 를 Github Actions 워크 플로우에서 접근하려면 권한이 필요합니다.
지금까지는 IAM 역할만 추가해서 특정 서비스 (EC2, CodeDeploy) 에게 부여 했지만 이번에는 IAM 사용자를 추가해봅니다.
5.1. IAM 사용자 메뉴로 이동
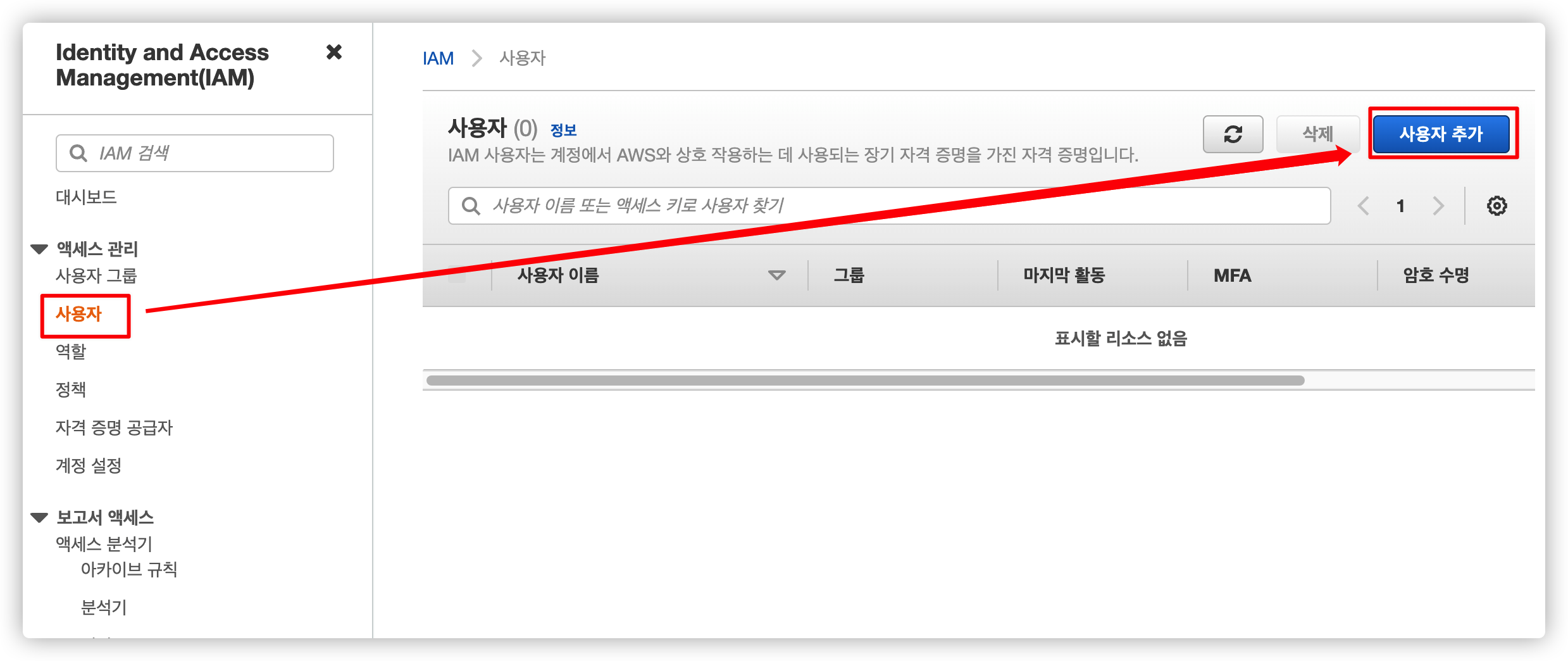
IAM 메뉴에서 사용자 추가를 선택합니다.
5.2. IAM 사용자 이름 및 액세스 유형 설정
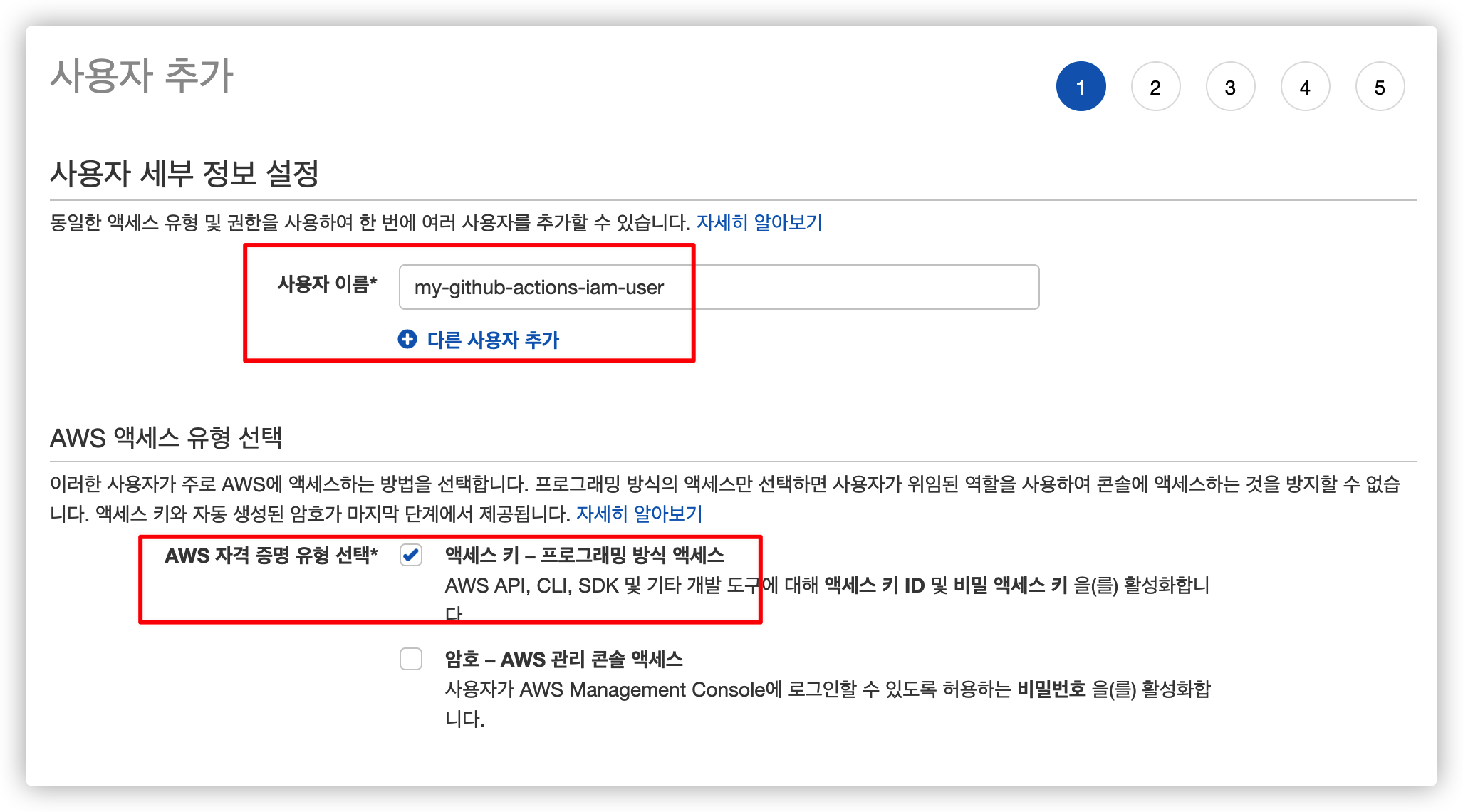
사용자 이름을 추가하고 액세스 유형을 선택합니다.
우리는 Github Actions 에서 사용해야 하기 때문에 암호 방식 대신 액세스 키 방식을 선택합니다.
5.3. 접근이 필요한 권한 추가
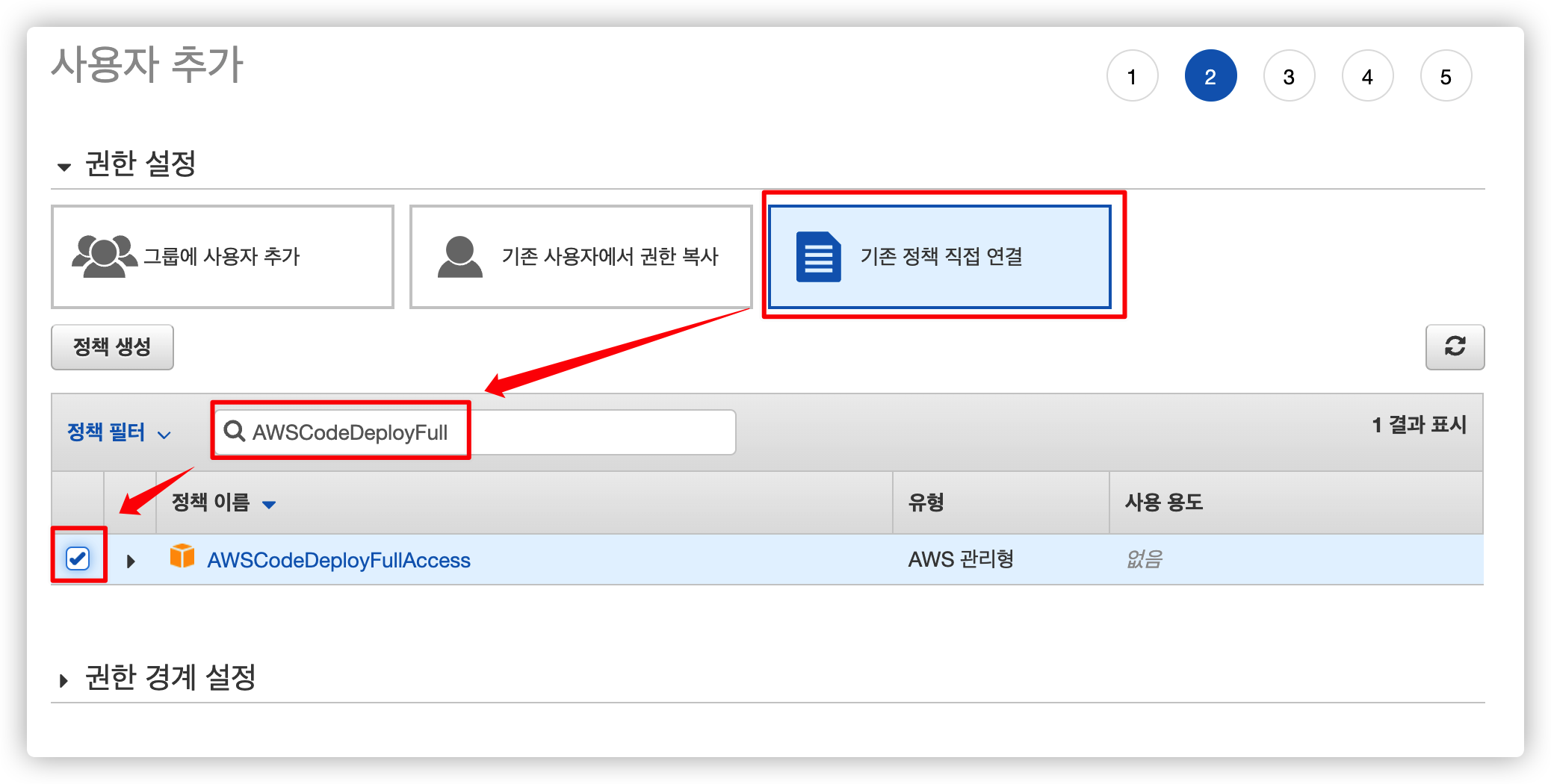
이 사용자에게 추가할 접근 권한을 고릅니다.
워크 플로우에서 CodeDeploy 를 실행해야 하기 때문에 다음 두 권한을 추가합니다.
- AWSCodeDeployFullAccess
- AmazonS3FullAccess
5.4. 사용자 만들기 완료
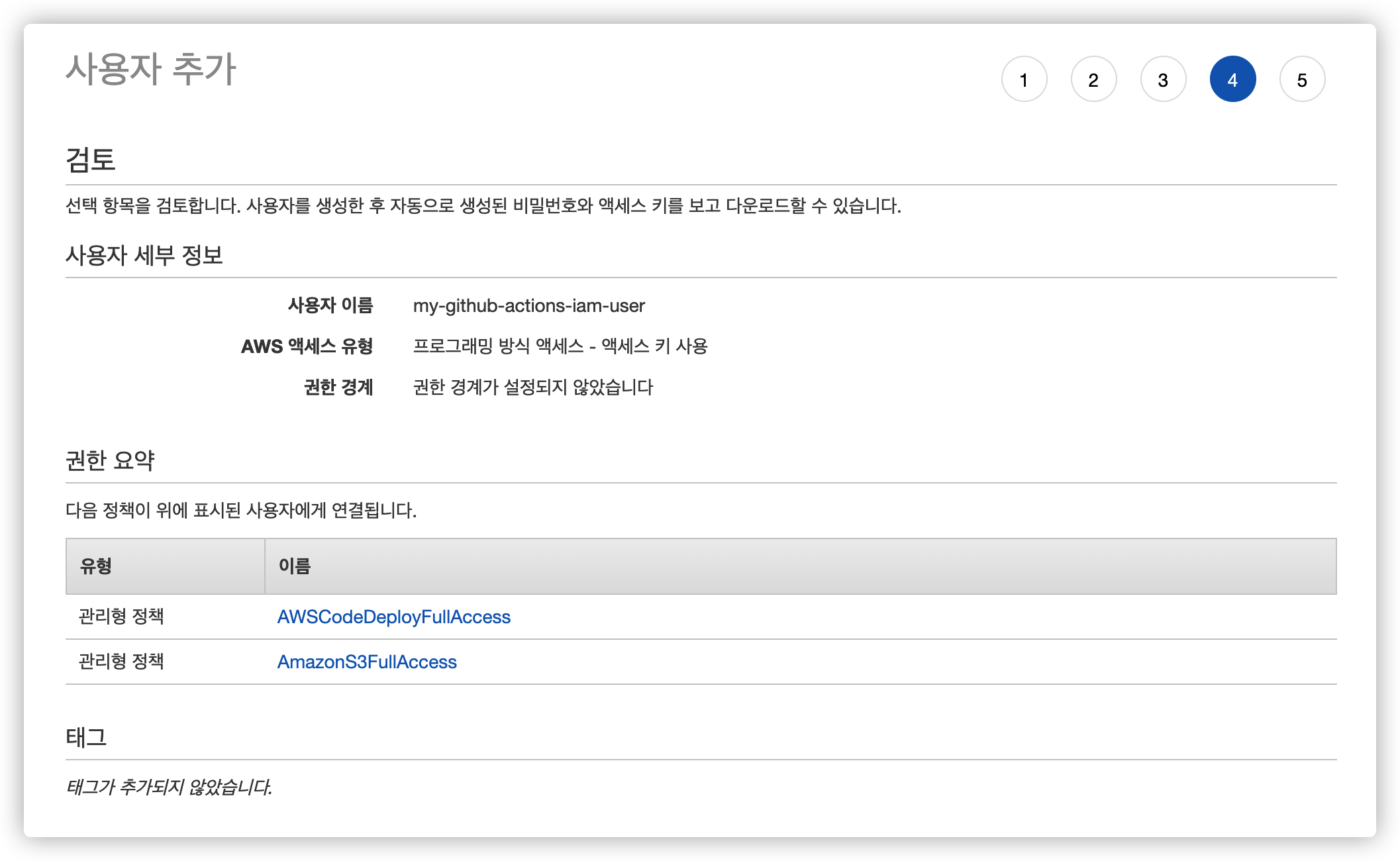
태그는 필요 없기 때문에 생략하고 잘못된 설정이 없는지 마지막으로 확인 후 사용자를 만듭니다.
5.5. Access Key 및 Secret Key 확인
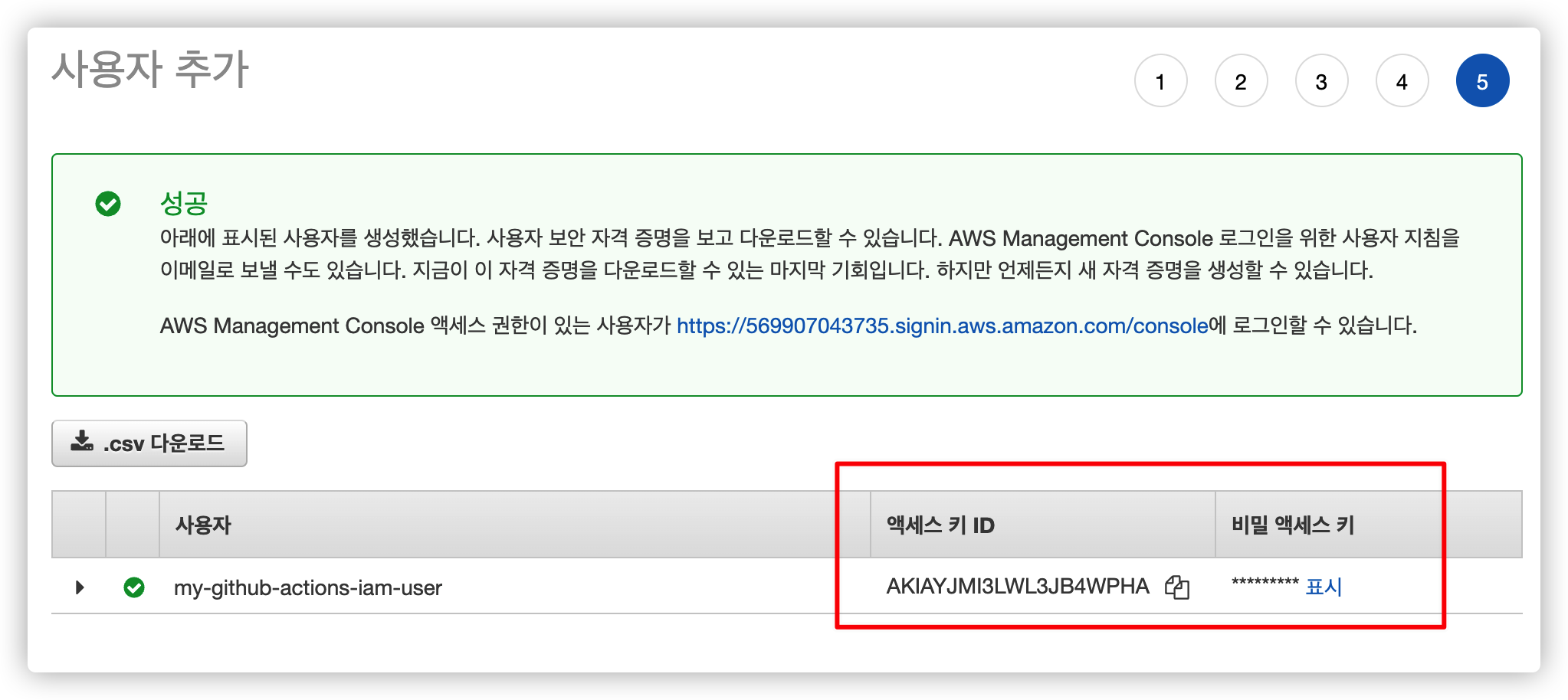
사용자를 만들고 나면 "액세스 키 ID" 와 "비밀 액세스 키" 가 존재합니다.
이 두 개의 키 값을 사용해서 IAM 권한을 획득할 수 있습니다.
우리는 이걸 Github Actions 에서 사용할 수 있도록 등록합니다.
5.6. Github Repository 의 Secrets 추가
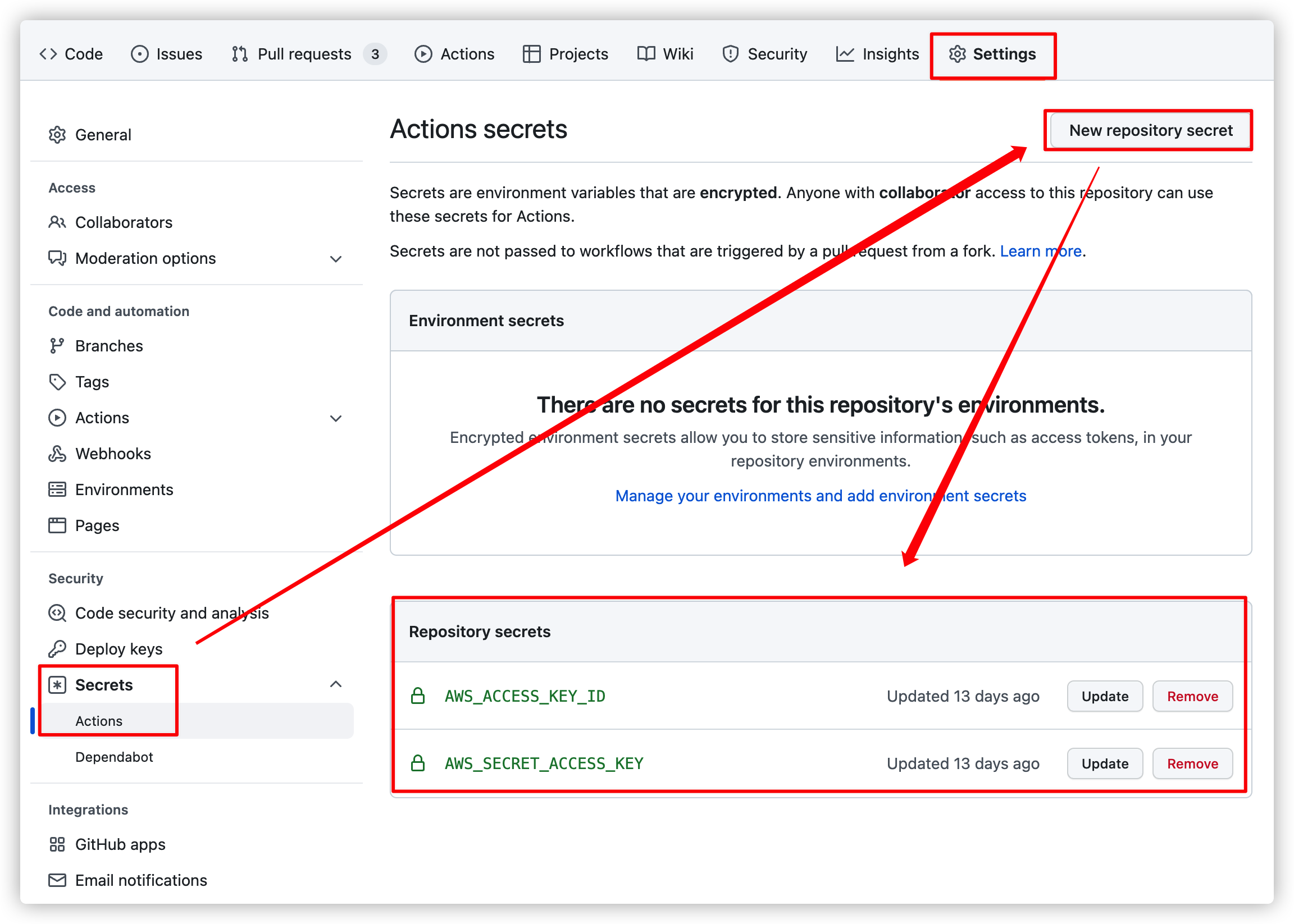
Github Actions 을 적용하려는 Github > Repository > Settings > Secrets 로 이동해서 위 키 값들을 등록합니다.
키 이름은 적당히 편한 것으로 설정합니다.
Github Secrets 에 저장한다고 해도 값을 직접 확인할 수 없기 때문에 필요한 경우 따로 저장해둡니다.
6. AppSpec 파일 작성
지금까지 우리는 서버를 띄울 EC2, 배포할 결과물을 저장할 S3, 배포를 도와줄 CodeDeploy 이렇게 총 세 가지 AWS 서비스를 만들었습니다.
이제 CodeDeploy 에서 배포를 위해 참조할 AppSpec 파일을 작성합니다.
AppSpec 파일을 사용해서 우리는 프로젝트의 어떤 파일들을 EC2 의 어떤 경로에 복사할지 설정 가능하고, 배포 프로세스 이후에 수행할 스크립트를 지정하여 자동으로 서버를 띄울 수도 있습니다.
AppSpec 파일은 기본적으로 루트 디렉터리에 위치해야 합니다.
version: 0.0
os: linux
files:
- source: /
destination: /home/ubuntu/app
overwrite: yes
permissions:
- object: /
pattern: "**"
owner: ubuntu
group: ubuntu
hooks:
AfterInstall:
- location: scripts/stop.sh
timeout: 60
runas: ubuntu
ApplicationStart:
- location: scripts/start.sh
timeout: 60
runas: ubuntu
전체 파일은 위와 같으며 각 섹션별로 조금씩만 살펴보겠습니다.
6.1. files 섹션
files:
- source: /
destination: /home/ubuntu/app
overwrite: yes
배포 파일에 대한 설정입니다.
- source: 인스턴스에 복사할 디렉터리 경로
- destination: 인스턴스에서 파일이 복사되는 위치
- overwrite: 복사할 위치에 파일이 있는 경우 대체
AppSpec "files" 섹션 문서를 참고하면 더 자세한 내용을 알 수 있습니다.
6.2. permissions 섹션
permissions:
- object: /
pattern: "**"
owner: ubuntu
group: ubuntu
files 섹션에서 복사한 파일에 대한 권한 설정입니다.
- object: 권한이 지정되는 파일 또는 디렉터리
- pattern (optional): 매칭되는 패턴에만 권한 부여
- owner (optional): object 의 소유자
- group (optional): object 의 그룹 이름
AppSpec "permissions" 섹션 문서를 참고하면 더 자세한 내용을 알 수 있습니다.
6.3. hooks 섹션
hooks:
AfterInstall:
- location: scripts/stop.sh
timeout: 60
runas: ubuntu
ApplicationStart:
- location: scripts/start.sh
timeout: 60
runas: ubuntu
배포 이후에 수행할 스크립트를 지정할 수 있습니다.
일련의 라이프사이클이 존재하기 때문에 적절한 Hook 을 찾아 실행할 스크립트를 지정하면 됩니다.
위 코드에서는 파일을 설치한 후 AfterInstall 에서 기존에 실행중이던 애플리케이션을 종료시키고 ApplicationStart 에서 새로운 애플리케이션을 실행합니다.
- location: hooks 에서 실행할 스크립트 위치
- timeout (optional): 스크립트 실행에 허용되는 최대 시간이며, 넘으면 배포 실패로 간주됨
- runas (optional): 스크립트를 실행하는 사용자
AppSpec "hooks" 섹션 문서를 참고하면 더 자세한 내용을 알 수 있습니다.
7. 배포 스크립트 작성
바로 위 AppSpec Hooks 에서 실행할 스크립트 stop.sh 와 start.sh 를 설정했습니다.
이제 수행할 스크립트 파일을 작성합니다.
7.1. stop.sh
#!/usr/bin/env bash
PROJECT_ROOT="/home/ubuntu/app"
JAR_FILE="$PROJECT_ROOT/spring-webapp.jar"
DEPLOY_LOG="$PROJECT_ROOT/deploy.log"
TIME_NOW=$(date +%c)
# 현재 구동 중인 애플리케이션 pid 확인
CURRENT_PID=$(pgrep -f $JAR_FILE)
# 프로세스가 켜져 있으면 종료
if [ -z $CURRENT_PID ]; then
echo "$TIME_NOW > 현재 실행중인 애플리케이션이 없습니다" >> $DEPLOY_LOG
else
echo "$TIME_NOW > 실행중인 $CURRENT_PID 애플리케이션 종료 " >> $DEPLOY_LOG
kill -15 $CURRENT_PID
fi
애플리케이션이 이미 떠있으면 종료하는 스크립트입니다.
간단히 주석으로 설명을 달아두었으니 쉘 스크립트를 작성할 줄 안다면 보기에 어려움은 없을 겁니다.
7.2. start.sh
#!/usr/bin/env bash
PROJECT_ROOT="/home/ubuntu/app"
JAR_FILE="$PROJECT_ROOT/spring-webapp.jar"
APP_LOG="$PROJECT_ROOT/application.log"
ERROR_LOG="$PROJECT_ROOT/error.log"
DEPLOY_LOG="$PROJECT_ROOT/deploy.log"
TIME_NOW=$(date +%c)
# build 파일 복사
echo "$TIME_NOW > $JAR_FILE 파일 복사" >> $DEPLOY_LOG
cp $PROJECT_ROOT/build/libs/*.jar $JAR_FILE
# jar 파일 실행
echo "$TIME_NOW > $JAR_FILE 파일 실행" >> $DEPLOY_LOG
nohup java -jar $JAR_FILE > $APP_LOG 2> $ERROR_LOG &
CURRENT_PID=$(pgrep -f $JAR_FILE)
echo "$TIME_NOW > 실행된 프로세스 아이디 $CURRENT_PID 입니다." >> $DEPLOY_LOG
애플리케이션을 실행하는 스크립트입니다.
Github Actions 워크플로우에서 이미 빌드는 마쳤기 때문에 JAR 파일만 복사 후 실행합니다.
7.3. build.gradle 파일 수정
위 스크립트를 보면 /build/libs/*.jar 파일을 $JAR_FILE 파일로 복사합니다.
그런데 Spring Boot 2.5 버전부터는 빌드 시 일반 jar 파일 하나와 -plain.jar 파일 하나가 함께 만들어집니다.
그래서 빌드 시 plain jar 파일은 만들어지지 않도록 build.gradle 파일에 다음 내용을 추가해야 합니다.
jar {
enabled = false
}
build.gradle.kts 파일은 이렇게 작성하시면 됩니다.
tasks.getByName<Jar>("jar") {
enabled = false
}
8. Github Actions Workflow 작성
이제 필요한 사전 작업은 모두 끝났으니 Github Actions 워크 플로우만 작성하면 됩니다.
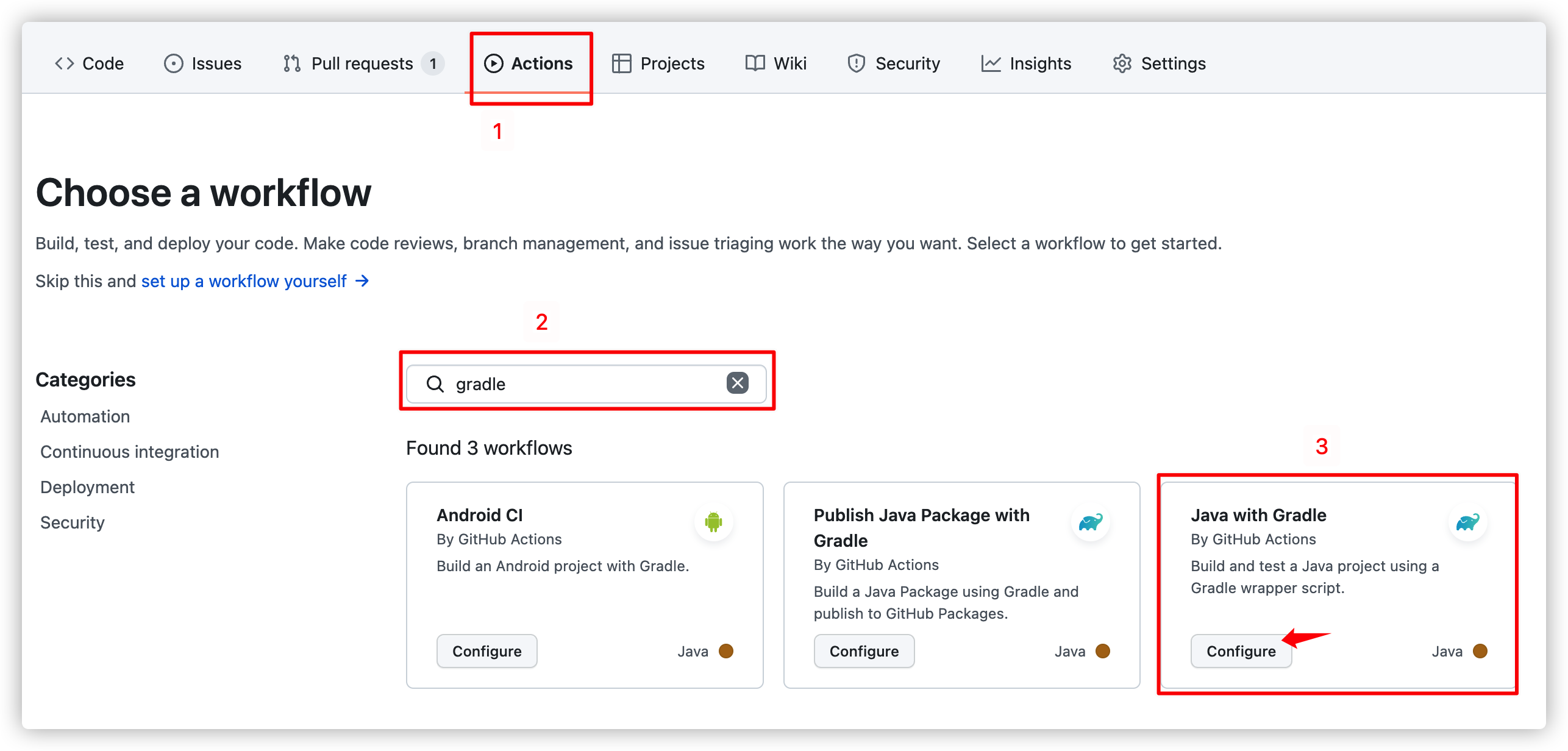
8.1. Sample Workflow 선택
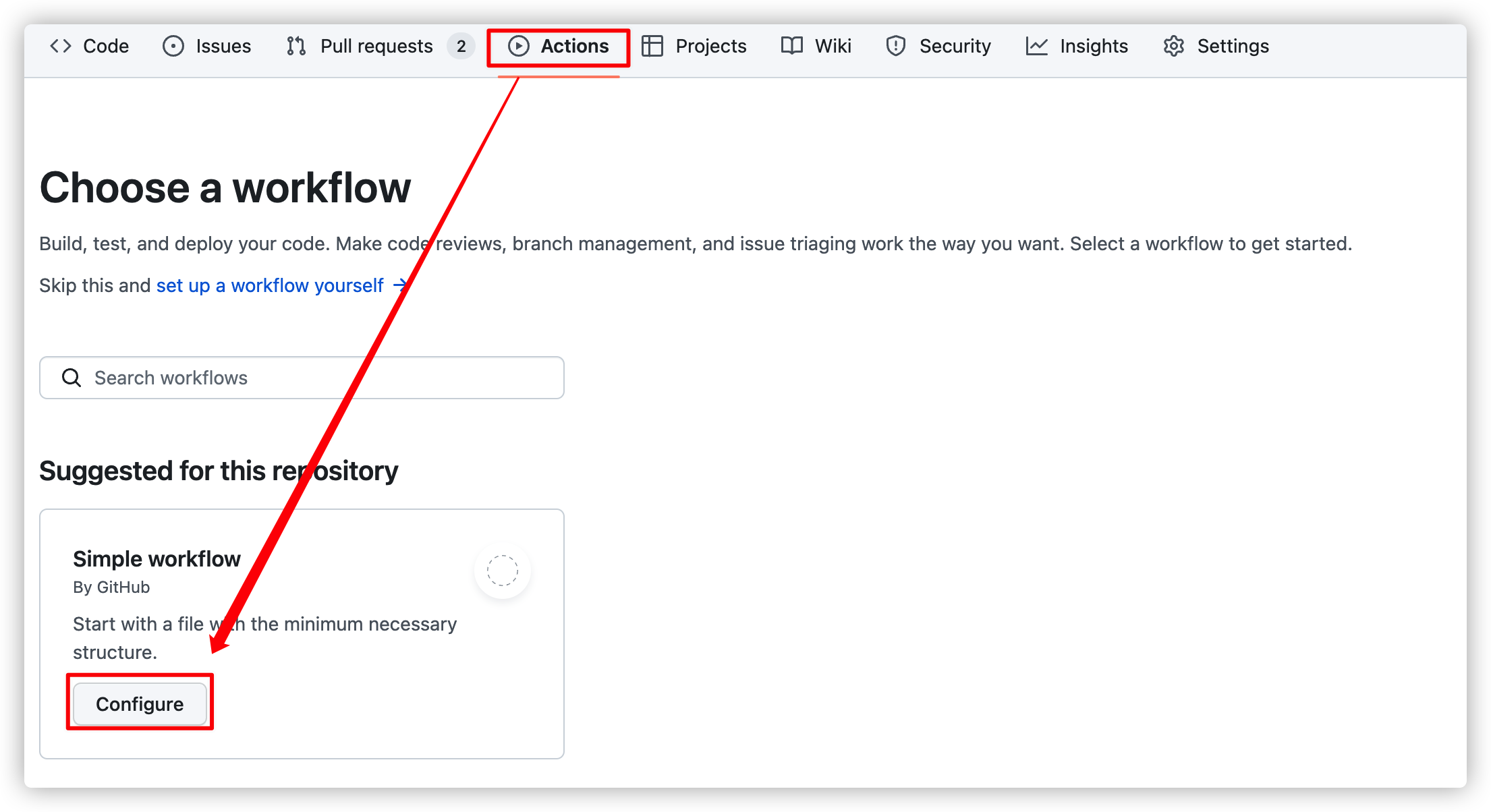
Github Actions CI 편에서는 기본적으로 제공되는 gradle 샘플을 수정했지만 배포 플로우는 거의 다 수정해야 하므로 그냥 가장 심플한 워크 플로우를 선택합니다.
8.2. deploy.yml 파일 작성
name: Deploy to Amazon EC2
on:
push:
branches:
- main
# 본인이 설정한 값을 여기서 채워넣습니다.
# 리전, 버킷 이름, CodeDeploy 앱 이름, CodeDeploy 배포 그룹 이름
env:
AWS_REGION: ap-northeast-2
S3_BUCKET_NAME: my-github-actions-s3-bucket
CODE_DEPLOY_APPLICATION_NAME: my-codedeploy-app
CODE_DEPLOY_DEPLOYMENT_GROUP_NAME: my-codedeploy-deployment-group
permissions:
contents: read
jobs:
deploy:
name: Deploy
runs-on: ubuntu-latest
environment: production
steps:
# (1) 기본 체크아웃
- name: Checkout
uses: actions/checkout@v3
# (2) JDK 11 세팅
- name: Set up JDK 11
uses: actions/setup-java@v3
with:
distribution: 'temurin'
java-version: '11'
# (3) Gradle build (Test 제외)
- name: Build with Gradle
uses: gradle/gradle-build-action@0d13054264b0bb894ded474f08ebb30921341cee
with:
arguments: clean build -x test
# (4) AWS 인증 (IAM 사용자 Access Key, Secret Key 활용)
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ env.AWS_REGION }}
# (5) 빌드 결과물을 S3 버킷에 업로드
- name: Upload to AWS S3
run: |
aws deploy push \
--application-name ${{ env.CODE_DEPLOY_APPLICATION_NAME }} \
--ignore-hidden-files \
--s3-location s3://$S3_BUCKET_NAME/$GITHUB_SHA.zip \
--source .
# (6) S3 버킷에 있는 파일을 대상으로 CodeDeploy 실행
- name: Deploy to AWS EC2 from S3
run: |
aws deploy create-deployment \
--application-name ${{ env.CODE_DEPLOY_APPLICATION_NAME }} \
--deployment-config-name CodeDeployDefault.AllAtOnce \
--deployment-group-name ${{ env.CODE_DEPLOY_DEPLOYMENT_GROUP_NAME }} \
--s3-location bucket=$S3_BUCKET_NAME,key=$GITHUB_SHA.zip,bundleType=zip
전체 파일은 위와 같으며 스텝 별로 간단한 주석을 달아두었습니다.
결국 프로젝트를 빌드한 후 AWS S3 버킷에 푸시 후 CodeDeploy 를 수행하는 겁니다.
(4), (5), (6) 에 대해서만 간략한 설명을 덧붙이겠습니다.
8.2.1. (4) AWS 인증
# (4) AWS 인증 (IAM 사용자 Access Key, Secret Key 활용)
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ env.AWS_REGION }}
AWS 에 접근하기 위해 인증하는 스텝입니다.
우리는 위에서 IAM 사용자를 만든 후 Access Key, Secret Key 를 Github 레포에 저장했습니다.
그러면 secrets 변수를 통해 우리가 저장한 키 값들을 가져와서 사용할 수 있습니다.
필요한 Access Key, Secret Key 등을 프로젝트 코드에 노출시키지 않은 채로 사용할 수 있다는 편리함이 있습니다.
8.2.2. (5) AWS S3 에 업로드
# (5) 빌드 결과물을 S3 버킷에 업로드
- name: Upload to AWS S3
run: |
aws deploy push \
--application-name ${{ env.CODE_DEPLOY_APPLICATION_NAME }} \
--s3-location s3://$S3_BUCKET_NAME/$GITHUB_SHA.zip \
--ignore-hidden-files \
--source .
원하는 파일들을 압축해서 AWS S3 에 업로드 하는 스텝입니다.
공식 문서를 참고하면 더 자세한 정보를 알 수 있습니다.
--application-name: CodeDeploy 애플리케이션 이름--s3-location: 압축 파일을 업로드 할 S3 버킷 정보--ignore-hidden-files (optional): 숨겨진 파일까지 번들링할지 여부
$GITHUB_SHA 라는 변수가 보이는데 간단하게 생각해서 Github 자체에서 커밋마다 생성하는 랜덤한 변수값입니다. (자세한 정보는 Github Context 참조)
이렇게 랜덤한 값을 사용하면 파일 업로드 시에 이름 중복으로 충돌날 일이 없습니다.
8.2.3. (6) AWS EC2 에 배포
# (6) S3 버킷에 있는 파일을 대상으로 CodeDeploy 실행
- name: Deploy to AWS EC2 from S3
run: |
aws deploy create-deployment \
--application-name ${{ env.CODE_DEPLOY_APPLICATION_NAME }} \
--deployment-config-name CodeDeployDefault.AllAtOnce \
--deployment-group-name ${{ env.CODE_DEPLOY_DEPLOYMENT_GROUP_NAME }} \
--s3-location bucket=$S3_BUCKET_NAME,key=$GITHUB_SHA.zip,bundleType=zip
위 스텝에서 S3 에 저장한 파일을 EC2 에서 땡겨온 후 압축을 풀고 스크립트를 실행합니다.
공식 문서를 참고하면 더 자세한 정보를 알 수 있습니다.
--application-name: CodeDeploy 애플리케이션 이름--deployment-config-name: 배포 방식인데 기본값을 사용--deployment-group-name: CodeDeploy 배포 그룹 이름--s3-location: 버킷 이름, 키 값, 번들타입
9. Github Actions 사용해서 배포하기
이제 모든 세팅이 끝났으므로 배포를 진행해봅니다.
yaml 파일로 설정한 것처럼 main 브랜치에 push 되는 경우 Github Actions Workflow 가 수행됩니다.
9.1. Github Repo 에서 확인
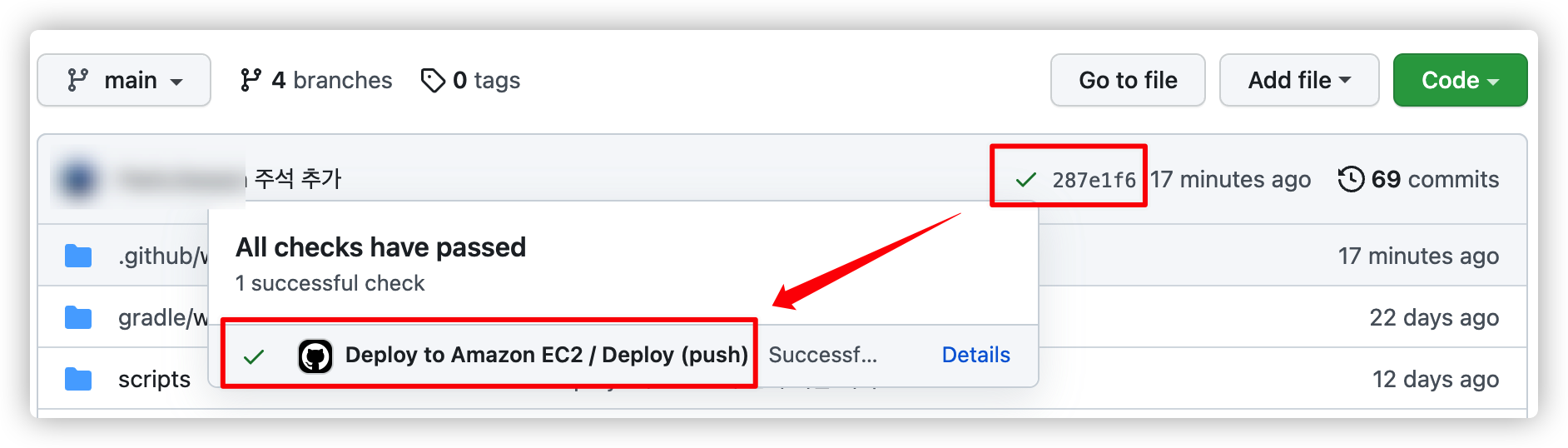
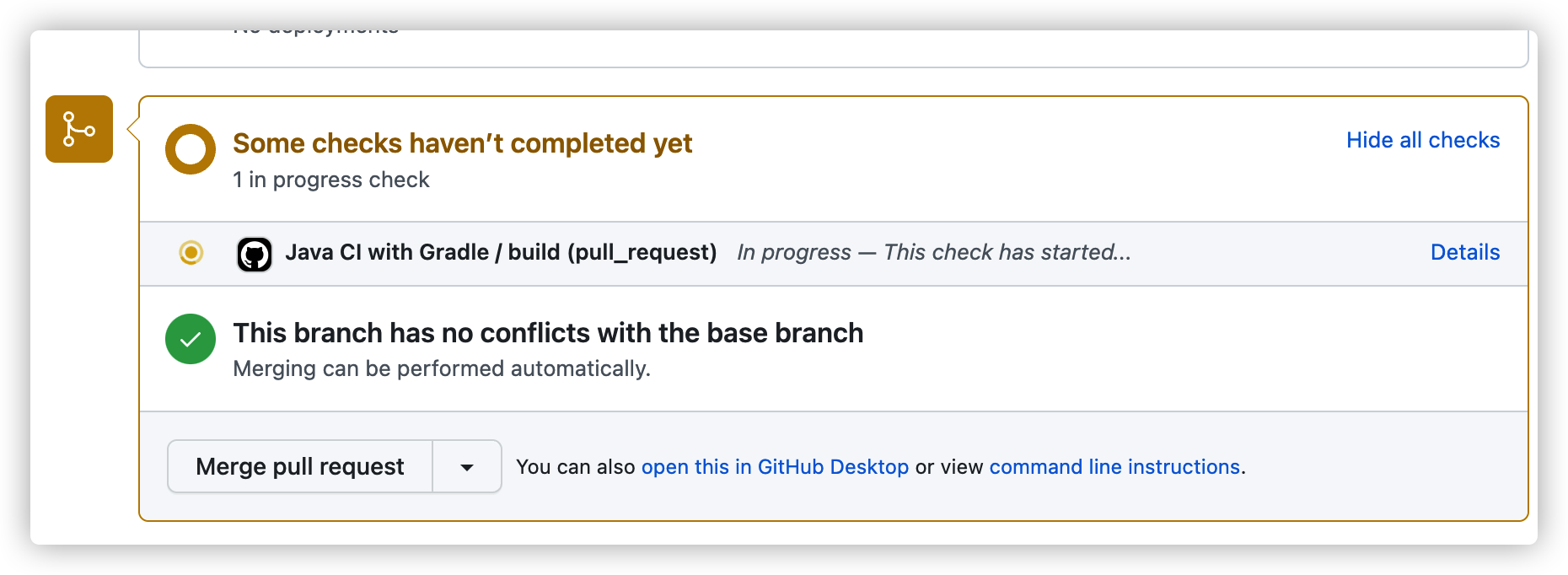
워크 플로우가 정상적으로 수행되면 이렇게 커밋에 체크 표시가 생깁니다.
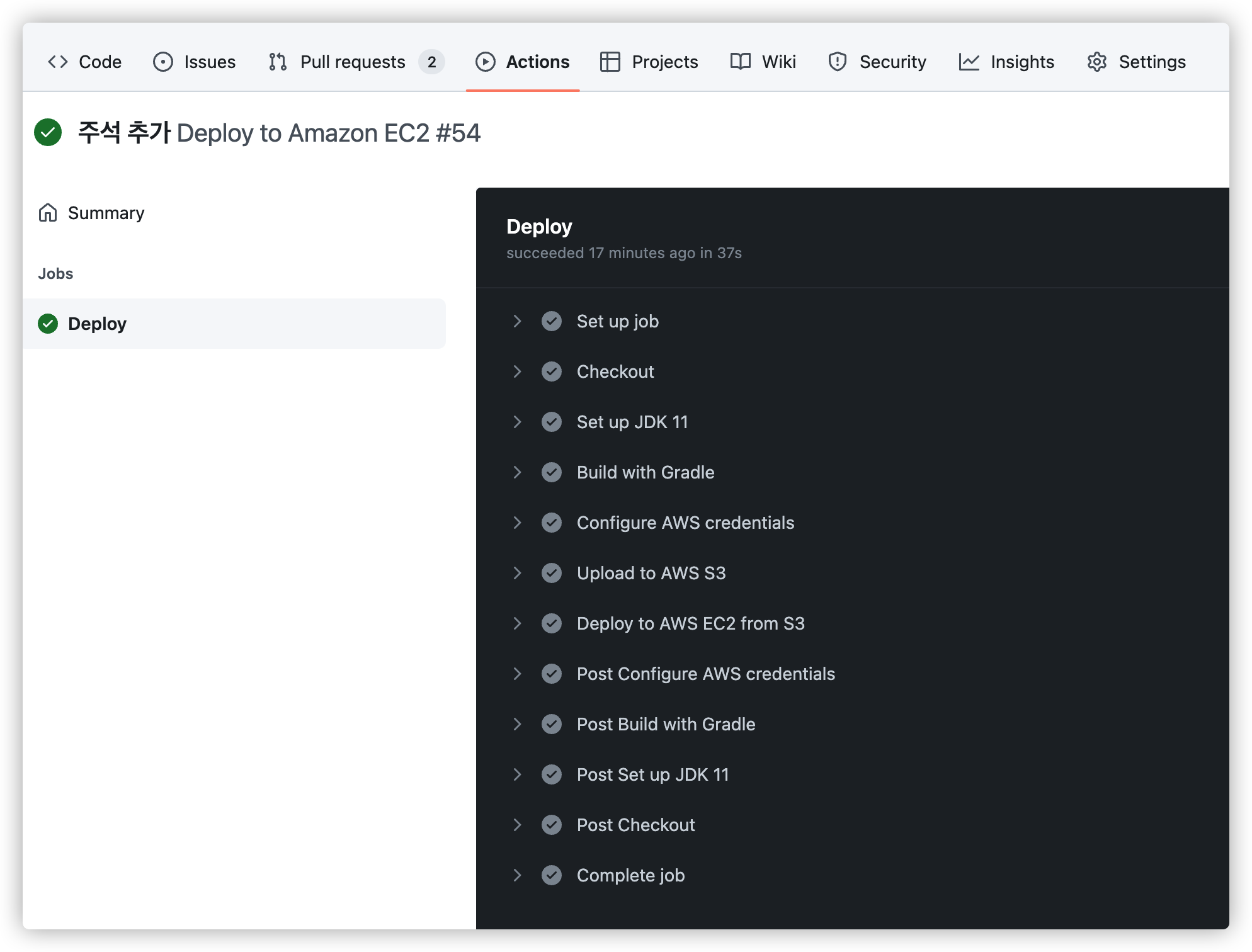
"Details" 를 눌러보거나 "Actions" 탭으로 이동하면 수행한 스텝이 나옵니다.
만약 실패한다면 어떤 스텝에서 실패했는지 확인할 수 있습니다.
9.2. CodeDeploy 에서 배포 내역 확인
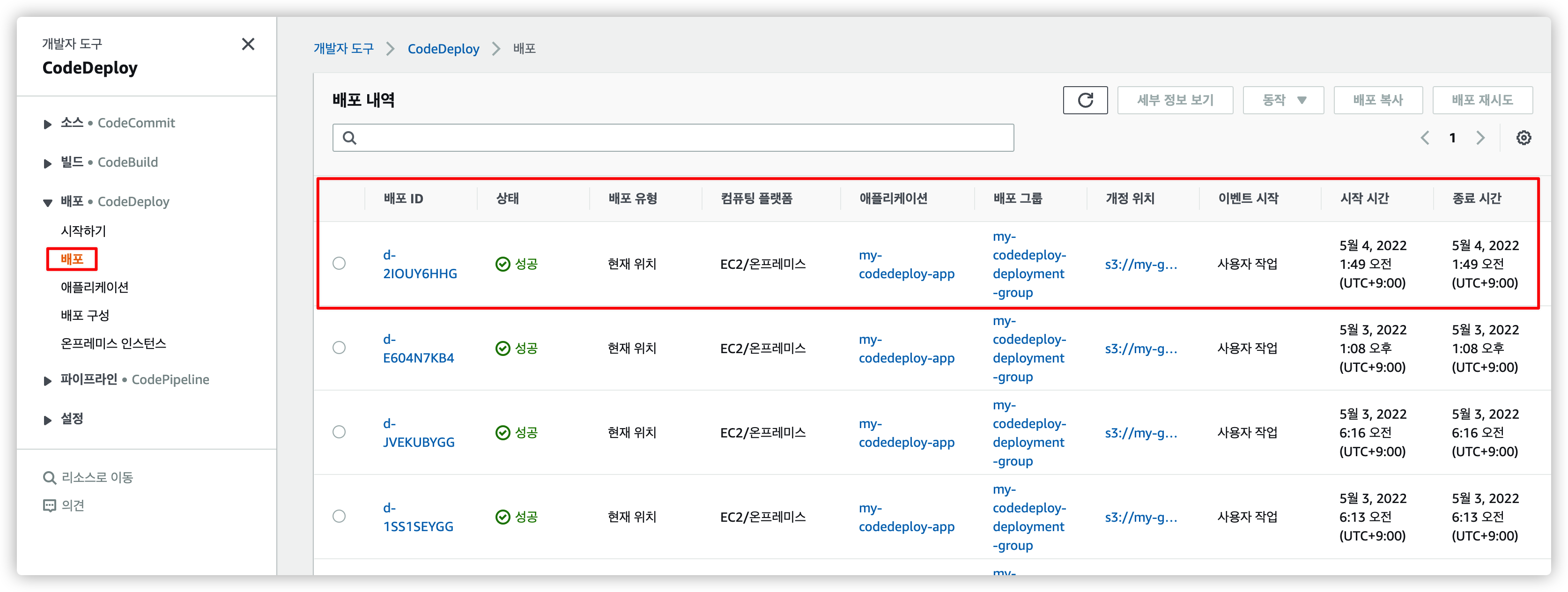
AWS CodeDeploy 메뉴로 이동하면 배포 내역을 확인인할 수 있습니다.
9.3. EC2 서버에서 애플리케이션 실행 확인
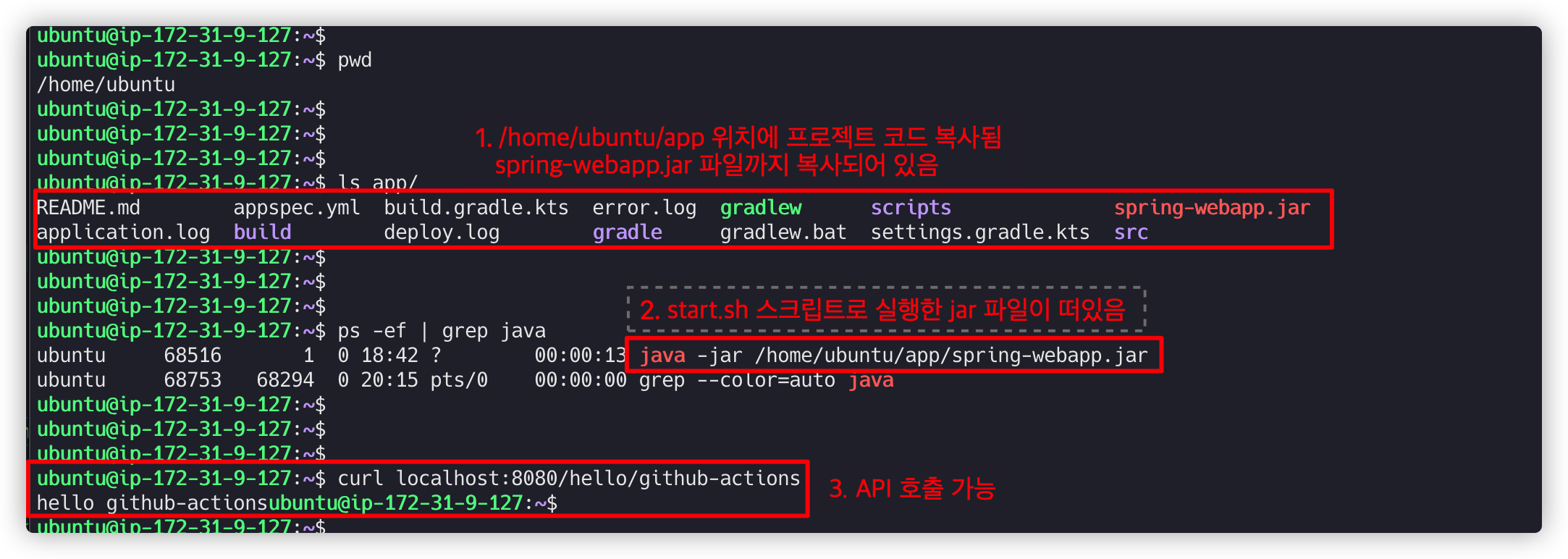
EC2 서버에 접속해서 확인 해보면 Spring Boot 프로젝트 코드가 있으며 서버도 정상적으로 떠있는 것을 확인할 수 있습니다.
- CodeDeploy 배포 로그 확인:
/var/log/aws/codedeploy-agent/codedeploy-agent.log
- CodeDeploy Hooks 로그 확인:
/opt/codedeploy-agent/deployment-root/deployment-logs/codedeploy-agent-deployments.log
Reference