순전히 개인적인 경험과 주관적인 의견으로 작성된 글입니다.
잘못된 정보가 있으면 지적 부탁드립니다.
Overview
웹플럭스는 흔히 비동기/논블로킹 이벤트루프 모델이라고 말합니다.
적은 수의 쓰레드로 많은 요청을 처리할 수 있는 걸 장점으로 내세우고 있는데, 항상 의문이 있었습니다.
흔히 블록킹 구간이라고 하는 네트워크 I/O 또는 데이터베이스 I/O 작업은 결국 어디선가 또는 누군가가 대기했다가 결과를 받아서 처리해야 합니다.
기존 MVC 모델에서 비동기 처리를 하면 별도의 쓰레드를 사용해서 처리했었기 때문에 큰 의문이 없었지만 쓰레드 하나로는 어떻게 처리하는지 궁금했습니다.
만약 웹플럭스에서도 별도 쓰레드풀을 만들어 처리한다면 요청량 증가에 따라 점점 백그라운드 쓰레드가 많아질거고 적은 수의 쓰레드로 컨텍스트 스위칭 비용 최소화 라는 장점이 무색해질 것 같았습니다.
이것저것 찾아본 결과 I/O 요청은 커널단으로 넘기고 JVM 은 I/O 요청에 필요한 데이터 복사만 해주기 때문에 블록킹 구간이 없다는 정보를 얻었습니다.
그렇다면 실제로 쓰레드가 처리해야 하는 연산이 오래 걸리는 경우에는 어떻게 될까? 라는 의문도 함께 들었습니다.
궁굼증을 해결하기 위해 코드를 짜서 테스트를 진행해보기로 했습니다.
전체 코드는 Github 에서 확인할 수 있습니다.
- 테스트 환경
- Kotlin / WebFlux 기반의 Spring Boot
- 쓰레드는 단 하나만 사용
- 테스트 내용
- WebClient 로 응답이 오래 걸리는 외부 API 요청 시 쓰레드가 블락되는가?
- 쓰레드가 처리해야 하는 무거운 연산 요청이 동시에 들어오면 비동기/논블로킹으로 처리 가능한가?
- 주의사항
- API 테스트를 할 때 동일 브라우저에서 여러 탭을 열어서 같은 요청을 보내면 순서대로 처리하기 때문에 시크릿 브라우저를 열어서 테스트 필요
1. 요청이 오래 걸리는 외부 API 를 요청하면 어떻게 될까?
Spring WebFlux 에서 외부 API 를 호출할 때는 WebClient 를 사용합니다.
WebClient 는 기존 MVC 모델에서 사용하던 RestTemplate 클래스와는 다르게 비동기로 API 를 호출하고 응답받을 수 있는 기능을 지원합니다.
WebClient 는 Spring WebFlux 에서 사용하는 이벤트 루프 워커 쓰레드를 공유합니다.
그래서 만약 외부 API 요청 시에 쓰레드가 Block 된다면 굉장한 문제가 생깁니다.
웹플럭스는 Core * 2 개의 쓰레드를 사용하기 때문에 많은 쓰레드를 사용하는 MVC 모델에 비해 쓰레드 블락의 영향이 큽니다.
1.1. 외부 API 서버 만들기
@SpringBootApplication
class ServerMvcApplication
fun main(args: Array<String>) {
System.setProperty("server.port", "8181")
runApplication<ServerMvcApplication>(*args)
}
@RestController
class BlockController {
val log: Logger = LoggerFactory.getLogger(BlockController::class.java)
@GetMapping("/block/{id}")
fun block(@PathVariable id: Long): ResponseEntity<String> {
log.info("request $id start")
Thread.sleep(5000)
log.info("request $id end")
return ResponseEntity.ok().body("response $id")
}
}API 요청을 받아 5초 뒤에 응답해주는 서버입니다.
일반적인 상황을 위해 외부 서버는 Spring Boot WebMVC 로 만들었습니다.
로컬에서 동시에 띄우기 위해 포트를 8181 로 변경하였고 /block/{id} API 를 요청하면 쓰레드를 5초동안 슬립시킨 후에 응답합니다.
MVC 모델은 요청마다 쓰레드를 하나씩 할당해서 처리하기 때문에 여러 요청이 들어와도 5초씩만 지연됩니다.

크롬 브라우저와 시크릿 브라우저에서 요청하면 별도 쓰레드에서 각각 요청을 처리하는 걸 볼 수 있습니다.
1.2. WebFlux 서버 만들기
위에서 만든 MVC 를 호출하는 웹플럭스 서버를 만들어봅니다.
1.2.1. Server Code
@SpringBootApplication
class ServerWebfluxApplication
fun main(args: Array<String>) {
// 쓰레드 1개만 사용
System.setProperty("reactor.netty.ioWorkerCount", "1")
runApplication<ServerWebfluxApplication>(*args)
}
@Configuration
class RouterConfig {
val log: Logger = LoggerFactory.getLogger(RouterConfig::class.java)
@Bean
fun route(handler: RouterHandler) = router {
"v1".nest {
GET("/call/{id}", handler::call)
before { request ->
log.info("Before Filter ${request.pathVariable("id")}")
log.info("$request")
request
}
after { request, response ->
log.info("After Filter ${request.pathVariable("id")}")
response
}
}
}
}
@Controller
class RouterHandler {
val log: Logger = LoggerFactory.getLogger(RouterHandler::class.java)
val webClient = WebClient.create("http://localhost:8181")
fun call(request: ServerRequest): Mono<ServerResponse> {
val id = request.pathVariable("id")
return webClient.get()
.uri("/block/$id")
.retrieve()
.bodyToMono(String::class.java)
.flatMap {
ServerResponse.ok().json().body(
Mono.just("[request $id] response $it")
)
}
}
}/v1/call/{id} 요청을 받으면 http://localhost:8181/block/{id} 호출한 결과값을 응답하는 API 입니다.
쓰레드 블록 여부를 판단해야 하기 때문에 워커 쓰레드 갯수를 1 개로 세팅합니다.
1.2.2. Thread Count

실제로 쓰레드가 한 개만 뜬 것을 확인할 수 있습니다.
요청은 모두 하나의 쓰레드로만 들어오며 쓰레드가 블락되는 경우 API 응답이 지연될 겁니다.
1.2.3. Log

쓰레드 하나로만 처리하는데도 Block 되지 않고 각각 5초만에 응답을 리턴합니다.
1.3. WebClient 대신 RestTemplate 을 사용하면?
@Controller
class RouterHandler {
fun rest(request: ServerRequest): Mono<ServerResponse> {
val id = request.pathVariable("id")
val restTemplate = RestTemplate()
val response = restTemplate.getForObject("http://localhost:8181/block/$id", String::class.java)
return ServerResponse.ok().json().body(
Mono.just(response!!)
)
}
}테스트 하는 김에 RestTemplate 으로도 테스트 해봤습니다.
/v1/rest/{id} 를 호출하면 쓰레드 1개를 블록시키기 때문에 요청이 순차적으로 처리됩니다.

일반 브라우저와 시크릿 브라우저에서 동시에 호출해도 순서대로 처리되는 걸 볼 수 있습니다.
2. 무거운 연산을 수행하는 경우에는 어떻게 될까?
API 요청은 논블로킹으로 처리하는데 무거운 연산을 쓰레드가 직접 수행하는 경우에는 어떻게 되는지 확인해봤습니다.
2.1. Server Code
@Controller
class RouterHandler {
val log: Logger = LoggerFactory.getLogger(RouterHandler::class.java)
fun heavy(request: ServerRequest): Mono<ServerResponse> {
val id = request.pathVariable("id")
(0..1_000_000_000).forEach {
if (it % 100_000_000 == 0) {
log.info("Request [$id] for: $it")
}
}
return ServerResponse.ok().json().body(
Mono.just("heavy response $id")
)
}
}for 문을 많이 돌면서 오래 걸리는 API 를 만들었습니다.
2.2. Log

위와 마찬가지로 쓰레드는 하나만 사용했습니다.
로그를 보면 알 수 있듯이 기존 요청을 처리하는 동안 대기했다가 순서대로 요청을 처리하는 것을 알 수 있습니다.
2.3. Response Time
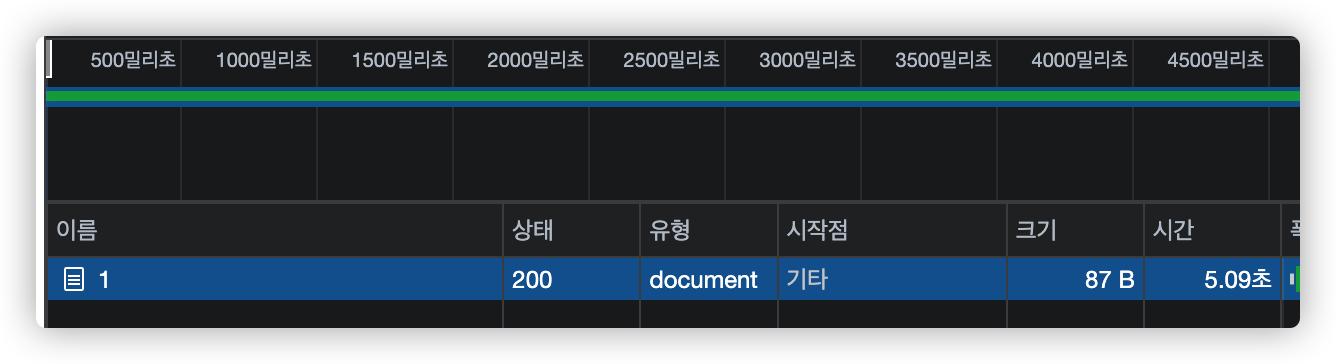

id=1 인 요청은 5초만에 응답했지만 id=2 인 경우에는 앞의 연산 때문에 지연되어 9초나 걸린 것을 확인할 수 있습니다.
Conclusion
직접 테스트를 해보니 인터넷에서 알아본 것처럼 NIO 쓰레드를 사용하면 I/O 요청 시 쓰레드가 대기하지 않고 다른 일을 처리할 수 있었습니다.
하지만 실제로 쓰레드가 일을 해야하는 무거운 연산을 수행하는 경우에는 응답이 지연되는 결과를 얻었습니다.
흔히 웹플럭스를 사용하기 좋은 환경으로 무거운 연산이 적고 I/O 위주의 로직이 존재하는 환경을 이야기합니다.
DB 를 연동할 때도 R2DBC 나 NoSQL 처럼 Reactive 모델을 지원하지 않는 경우 블로킹 구간이 발생해서 사용할 수 없다 라고도 말합니다.
그동안은 막연하게 생각해오기만 했는데 실제로 테스트 해서 눈으로 확인해보니 이유를 알 수 있었습니다.
'Framework > Spring' 카테고리의 다른 글
| Spring Boot 에서 Kakao, Naver 로그인하기 2편 (OAuth 2.0) - 코드 구현 (12) | 2023.03.12 |
|---|---|
| Spring Boot 에서 Kakao, Naver 로그인하기 1편 (OAuth 2.0) - 앱 등록 (0) | 2023.03.12 |
| JPA Batch Size (0) | 2021.09.14 |
| JPA Entity 삭제: orphanRemoval vs CascadeType.REMOVE (0) | 2021.08.28 |
| JPA 연관 관계 (일대일, 다대일, 단방향, 양방향) (0) | 2021.08.27 |