Overview
Spring Boot 에서 Cache 를 적용하는 방법에 대해 알아봅니다.
원래 Cache 를 사용할 때 Redis 같은 별도의 글로벌 저장소를 활용하는게 일반적이지만 이번에는 간단하게 기본 캐시인 ConcurrentMapCache 를 사용합니다.
1. Dependency 추가
implementation 'org.springframework.boot:spring-boot-starter-cache'
사실 spring-boot-starter-cache 를 추가하지 않아도 캐시 기능을 사용할 수 있습니다.
spring-boot-starter-web 같은 스타터 모듈에 자동으로 포함되어 있는 spring-context 라는 모듈 덕분인데요.
Spring Boot 3.0.5 가이드를 보면 spring-boot-starter-cache 모듈을 추가해야 spring-context-support 모듈을 가져와서 캐시 관련된 여러 기능을 제공하기 때문에 캐시 관련 의존성을 추가해준다고 합니다.
2. Configuration
@EnableCaching
@Configuration
public class CachingConfig {
@Bean
public CacheManager cacheManager() {
ConcurrentMapCacheManager cacheManager = new ConcurrentMapCacheManager();
cacheManager.setAllowNullValues(false);
cacheManager.setCacheNames(List.of("members"));
return cacheManager;
}
}
다음은 Cache 관련 설정을 추가합니다.
@EnableCaching 은 SpringBootApplication 에 추가해도 되지만 어차피 캐시 설정을 위해 Config 클래스를 추가할 거라면 여기에 추가해도 됩니다.
2.1. Cache Customizer
@Component
public class SimpleCacheCustomizer implements CacheManagerCustomizer<ConcurrentMapCacheManager> {
@Override
public void customize(ConcurrentMapCacheManager cacheManager) {
cacheManager.setAllowNullValues(false);
}
}
Cache Customizer 를 따로 추가하는 방법도 있습니다.
3. Cache 어노테이션
설정을 마쳤으니 Cache 관련 어노테이션을 사용하면 손쉽게 캐시 기능을 사용할 수 있습니다.
캐시 어노테이션들은 기본적으로 AOP 로 동작하기 때문에 내부 호출 같은 이슈를 주의해야 합니다.
@Cacheable
- 데이터를 캐시에 저장
- 메서드를 호출할 때 캐시의 이름 (
value) 과 키 (key) 를 확인하여 이미 저장된 데이터가 있으면 해당 데이터를 리턴
- 만약 데이터가 없다면 메서드를 수행 후 결과값을 저장
@CachePut
@Cacheable 과 비슷하게 데이터를 캐시에 저장- 차이점은
@Cacheable 은 캐시에 데이터가 이미 존재하면 메서드를 수행하지 않지만 @CachePut 은 항상 메서드를 수행
- 그래서 주로 캐시 데이터를 갱신할 때 많이 사용
@CacheEvict
@CacheConfig
- 메서드가 아닌 클래스에 붙여서 공통된 캐시 기능을 모을 수 있음
- 예를 들면
cacheNames, cacheManager 등등
@Caching
- Cacheable, CachePut, CacheEvict 를 여러 개 사용할 때 묶어주는 기능
일반적으로 @Cacheable 을 사용해서 캐싱하고 데이터를 갱신할 때 @CachePut, @CacheEvict 중 하나를 선택해서 갱신합니다.
@CachePut 을 사용하면 @Cacheable 데이터 조회 시 캐시에 새로운 데이터가 존재하기 때문에 DB 조회를 하지 않아도 된다는 장점이 있습니다.
4. Domain 정의
이제 캐시를 적용하기 전에 간단하게 필요한 클래스들을 정의해봅니다.
4.1. Member
@Getter
@Setter
@ToString
@NoArgsConstructor
public class Member {
private Long id;
private String name;
private Integer age;
public Member(String name, Integer age) {
this.name = name;
this.age = age;
}
}
캐싱 대상인 Member 클래스입니다.
Lombok 을 사용했고 복잡한 데이터 없이 간단하게 만들었습니다.
4.2. Members (List)
@Getter
@ToString
@NoArgsConstructor
public class Members {
private List<Member> members = new ArrayList<>();
public Members(List<Member> members) {
this.members = members;
}
}
마찬가지로 캐시 대상인 Members 입니다.
List<Member> 를 담은 일급 컬렉션이고 특별한 건 없습니다.
5. MemberRepository
@Slf4j
@Repository
@CacheConfig(cacheNames = "members")
public class MemberRepository {
private final Map<Long, Member> store = new LinkedHashMap<>();
@Cacheable(key = "'all'")
public Members findAll() {
List<Member> members = store.values().stream().toList();
log.info("Repository findAll {}", members);
return new Members(members);
}
@Cacheable(key = "#memberId", unless = "#result == null")
public Member findById(Long memberId) {
Member member = store.get(memberId);
log.info("Repository find {}", member);
return member;
}
@CachePut(key = "#member.id")
@CacheEvict(key = "'all'")
public Member save(Member member) {
Long newId = calculateId();
member.setId(newId);
log.info("Repository save {}", member);
store.put(member.getId(), member);
return member;
}
private Long calculateId() {
if (store.isEmpty()) {
return 1L;
}
int lastIndex = store.size() - 1;
return (Long) store.keySet().toArray()[lastIndex] + 1;
}
@CachePut(key = "#member.id")
@CacheEvict(key = "'all'")
public Member update(Member member) {
log.info("Repository update {}", member);
store.put(member.getId(), member);
return member;
}
@Caching(evict = {
@CacheEvict(key = "'all'"),
@CacheEvict(key = "#member.id")
})
public void delete(Member member) {
log.info("Repository delete {}", member);
store.remove(member.getId());
}
}
캐시 어노테이션을 적용한 MemberRepository 코드입니다.
데이터는 실제 DB 대신 간단하게 LinkedHashMap 을 사용했습니다.
우선 전체 코드를 보고 하나씩 살펴봅니다.
5.1. @CacheConfig
@CacheConfig 를 클래스에 붙여서 members 라는 공통 캐시 이름을 설정합니다.
5.2. 복수 조회 (findAll)
@Cacheable(key = "'all'")
public Members findAll() {
List<Member> members = store.values().stream().toList();
log.info("Repository findAll {}", members);
return new Members(members);
}
전체 데이터를 조회하는 메서드입니다.
key 를 all 로 설정했기 때문에 members::all 이라는 key 값에 Members 데이터가 저장됩니다.
이후에 한번 더 조회를 하면 members::all 을 확인하고 데이터가 있다면 그 값을 그대로 리턴합니다.
5.3. 단건 조회 (findById)
@Cacheable(key = "#memberId", unless = "#result == null")
public Member findById(Long memberId) {
Member member = store.get(memberId);
log.info("Repository find {}", member);
return member;
}
Member 데이터를 저장하는 단건 조회 메서드입니다.
memberId 를 키값으로 설정하며 unless = "#result == null" 조건을 추가하여 DB 에 없는 데이터인 경우 캐싱하지 않도록 했습니다.
만약 이 조건을 추가하지 않으면 null 값도 캐싱 대상이 됩니다.
우리는 캐시 설정에서 cacheManager.setAllowNullValues(false); 를 추가했기 때문에 null 값을 캐싱하려고 하면 에러가 발생하니 꼭 위 조건을 함께 추가해줘야 합니다.
5.4. 생성 및 변경 (save & update)
@CachePut(key = "#member.id")
@CacheEvict(key = "'all'")
public Member save(Member member) {
Long newId = calculateId();
member.setId(newId);
log.info("Repository save {}", member);
store.put(member.getId(), member);
return member;
}
@CachePut(key = "#member.id")
@CacheEvict(key = "'all'")
public Member update(Member member) {
log.info("Repository update {}", member);
store.put(member.getId(), member);
return member;
}
새로운 데이터를 저장합니다.
여기에는 두가지 어노테이션이 붙어 있는데 @CachePut 은 새로운 데이터를 저장하면 해당 데이터를 바로 캐싱하기 위해 추가했습니다.
여기서 캐싱하지 않아도 조회할 때 캐싱되기 때문에 반드시 필요한 설정은 아닙니다.
@CacheEvict 는 전체 조회 데이터를 삭제합니다.
2개의 데이터가 캐싱되어 있고 새로운 데이터가 추가되었는데 캐시를 갱신하거나 비워주지 않으면 만료될 때까지 이전 데이터를 보고 있기 때문에 한번 삭제해줘야 합니다.
단건 조회라면 @CachePut 을 사용해서 갱신할 수 있지만 복수 조회라면 갱신하는 일이 더 귀찮기 때문에 그냥 캐시를 비워주고 findAll 을 호출할 때 새로 캐싱합니다.
@CachePut 을 사용할 때 한가지 주의할 점이라면 반환값을 캐싱하기 때문에 void update 처럼 리턴값을 제대로 지정하지 않는 경우 제대로 동작하지 않을 수 있습니다.
5.5. 삭제 (delete)
@Caching(evict = {
@CacheEvict(key = "'all'"),
@CacheEvict(key = "#member.id")
})
public void delete(Member member) {
log.info("Repository delete {}", member);
store.remove(member.getId());
}
Member 데이터를 삭제합니다.
삭제는 Member 데이터와 Members 데이터의 캐싱을 모두 없애줘야 하기 때문에 @CacheEvict 을 두개 사용했습니다.
메서드에는 중복된 어노테이션을 두개 붙일 수 없기 때문에 @Caching 을 사용해서 묶어주면 동일한 어노테이션 두개를 전부 적용할 수 있습니다.
6. MemberController
@Slf4j
@RestController
@RequiredArgsConstructor
public class MemberController {
private final MemberRepository memberRepository;
@GetMapping("/members")
public Members findAll() {
Members members = memberRepository.findAll();
log.info("Controller findAll {}", members);
return members;
}
@GetMapping("/members/{memberId}")
public Member findById(@PathVariable Long memberId) {
Member member = memberRepository.findById(memberId);
log.info("Controller find {}", member);
return member;
}
@PostMapping("/members")
public Member save(@RequestBody MemberDto memberDto) {
Member member = new Member(memberDto.getName(), memberDto.getAge());
Member savedMember = memberRepository.save(member);
log.info("Controller save {}", savedMember);
return savedMember;
}
@PutMapping("/members/{memberId}")
public Member update(@PathVariable Long memberId, @RequestBody MemberDto memberDto) {
Member member = new Member(memberDto.getName(), memberDto.getAge());
member.setId(memberId);
return memberRepository.update(member);
}
@DeleteMapping("/members/{memberId}")
public void delete(@PathVariable Long memberId) {
Member member = memberRepository.findById(memberId);
log.info("Controller delete {}", member);
memberRepository.delete(member);
}
}
간단한 CRUD REST API 를 만들었습니다.
7. API Test
로컬에서 실제 테스트를 진행해봅니다.
7.1. 빈 List 조회

우선 아무것도 추가하지 않은 상태로 데이터를 조회해봅니다.
처음에는 Repository 로그까지 남지만 똑같은 요청을 반복하면 캐싱된 데이터를 가져오므로 Controller 까지만 로그가 남습니다.
7.2. 새로운 데이터 추가
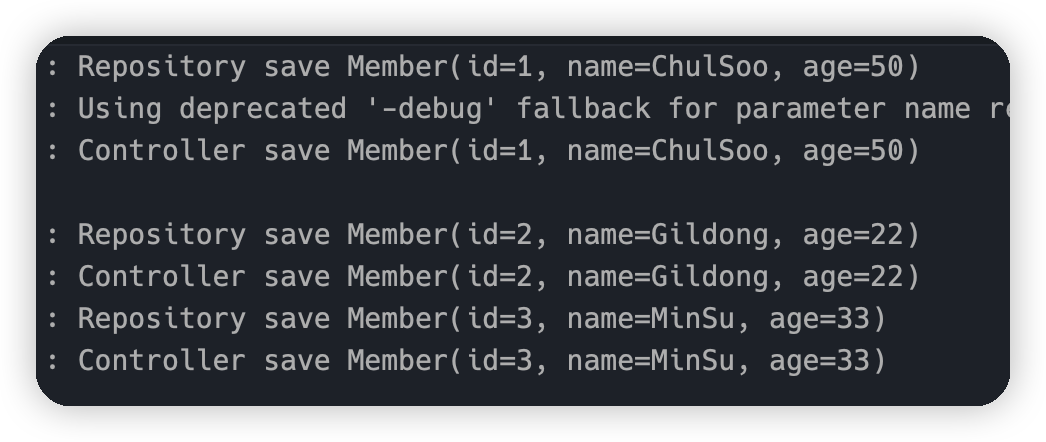
새로운 데이터를 추가합니다.
데이터 추가나 변경은 @CachePut 을 사용하기 때문에 매번 Repository 로그를 남깁니다.
7.3. Members 새로운 데이터 조회

다시 findAll 을 호출합니다.
새로운 데이터를 추가할 때마다 members::all 은 evict 되어 다시 Repository 조회까지 수행합니다.
하지만 한번 조회한 이후에는 여전히 Controller 로그까지만 남깁니다.
7.4. Member 단건 조회

단건 조회를 해도 @CachePut 으로 members::2 가 이미 캐싱되어 있기 때문에 Repository 로그는 남지 않습니다.
Conclusion
Cache 는 서버 개발을 하는데 굉장히 중요한 기능입니다.
대부분의 성능 개선을 캐시 추가로 할 수 있으며 설정도 다양하고 캐시 전략도 다양합니다.
Spring Boot 에서는 Cache 를 사용하기 쉽게 AOP 로 제공하고 있으니 사용법을 알아두면 필요할 때 유용하게 사용할 수 있습니다.
Reference




